네이버 API를 이용해서 프로그래밍 언어책들을 조사해보자
다음 과제는 pinklab의 민형기 강사님의 수업자료를 바탕으로 만들어졌습니다.
PinkLAB
핑크랩은 머신러닝, 딥러닝의 데이터 사이언스와 로봇 SW에 대한 교육 컨텐츠를 개발하고, 기업의 데이터 기반 프로젝트나 로봇 개발 프로젝트를 매우 효율적인 방법으로 도울 수 있는 방법을
www.pinklab.art
TIOBE INDEX의 상위 9개 언어에 R까지 해서 총 10개 언어에 대해 출판 책 정보를 수집하세요.
문제1 : 상위 10개의 출판정보를 수집하세요.
어떤 방식으로 접근해야할지 고민해보자.
상위 10개의 언어정보를 가져와야하니 크롤링을 손수한다면 아마 상당히 어려울 것이라 생각한다. 그래서 이 문제는 네이버API를 통해서 접근하는 것이 좋다고 판단했다.
나는 이 부분에서 유리했는데, 이전 블로그에서 관련 글을 작성해본 경험 때문에 남들보다 빠르게 끝낼 수 있었다.
(네이버 API를 사용하는 방법을 정리한 블로그 글)
5. 네이버 API를 이용해서 그래픽카드 특가를 노려보자 (1/2) (tistory.com)
5. 네이버 API를 이용해서 그래픽카드 특가를 노려보자 (1/2)
3. crawling을 통해 그래픽카드의 특가를 노려보자. (tistory.com) 3. crawling을 통해 그래픽카드의 특가를 노려보자. 들어가기전 pinkwink 강사님께서 수업자료와 관련되어 실습을 스스로 진행하여 블로그
kimbrain.tistory.com
(데이터를 분석하는 방법을 정리해보면서 이 상황에서 어떤 지표가 도움이 될지 확인해볼 수 있었습니다.)
4. (daily project)세계 테러 데이터 분석하기 (tistory.com)
4. (daily project)세계 테러 데이터 분석하기
PinkWink PinkWink 한 변두리 공학도의 블로그입니다. 재미있어 보이는 것들을 모두 기초스럽게 접근하는 블로그이며... 그보다 더욱 소중한 우리 아가 미바뤼의 발자취를 남겨두는 블로그이기도 합
kimbrain.tistory.com
여튼 바로 시작하면
import os
import sys
import urllib.request
client_id = 네이버 API ID
client_secret = 네이버 API secret
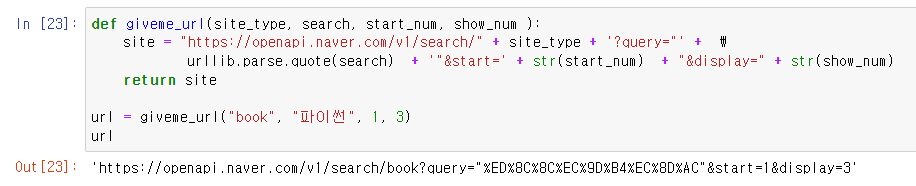
def giveme_url(site_type, search, start_num, show_num ):
site = "https://openapi.naver.com/v1/search/" + site_type + '?query="' + \
urllib.parse.quote(search) + '"&start=' + str(start_num) + "&display=" + str(show_num)
return site
url = giveme_url("book", "파이썬", 1, 3)
url네이버 API에서 사용할 URL을 만들어내는 함수입니다.
import json
def giveme_code(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request)
print("*")
return json.loads(response.read().decode("utf-8"))
url = giveme_url("book", "파이썬", 1, 3)
code = giveme_code(url)
codeurl과 ID, Secret을 통해서 관련 정보를 받아오는 코드입니다. -> 이는 네이버 API에 가면 예제를 함수로 만든 것이기 때문에 코드 설명은 생략하도록 하죠.
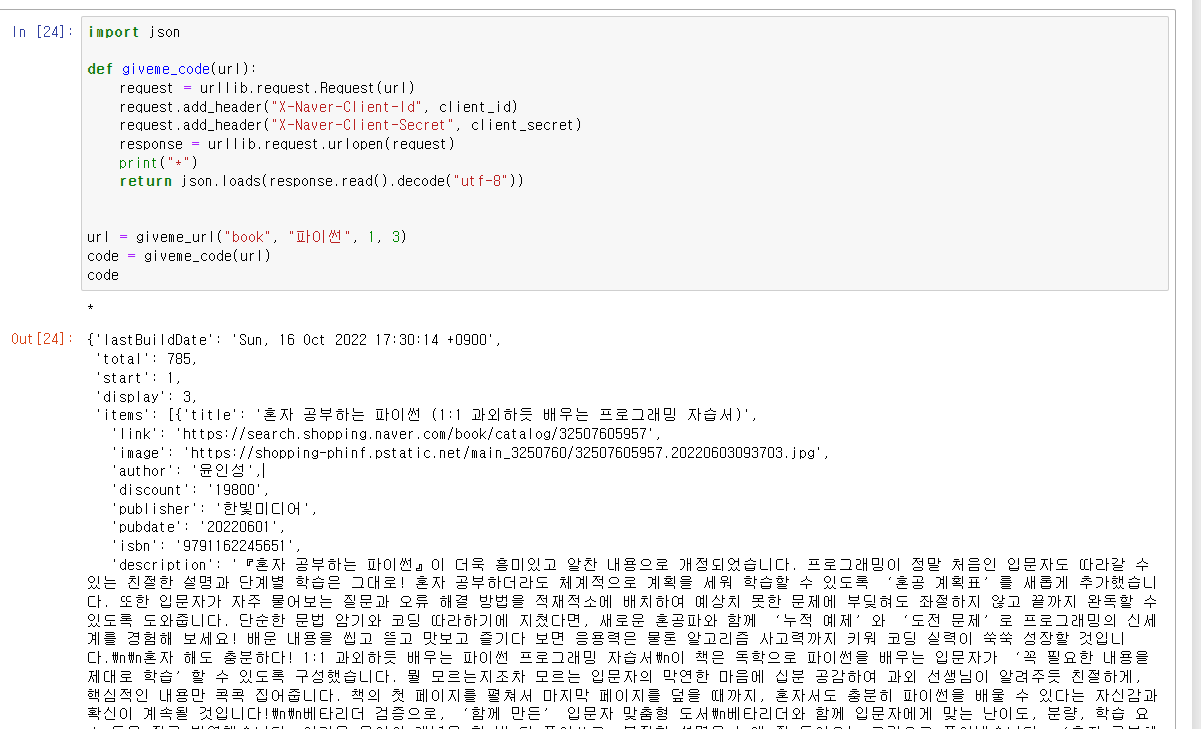
해당 코드를 실행하면
book : 네이버 책에서 파이썬을 검색해서 1page에서 3개의 정보만 가져다가 주세요.
를 통해서 3개의 정보를 추출해냅니다.

그러면 다음처럼 정보들을 추출해낼 수 있겠죠. 필요한 정보를 추출하는 함수로 나타내면
import pandas as pd
def save_info(data):
title = [each["title"] for each in data["items"]]
author = [each["author"] for each in data["items"]]
discount = [each["discount"] for each in data["items"]]
publisher = [each["publisher"] for each in data["items"]]
pubdate = [each["pubdate"] for each in data["items"]]
isbn = [each["isbn"] for each in data["items"]]
result = pd.DataFrame({
"제목" : title,
"저자" : author,
"출판사" : publisher,
"출판일" : pubdate,
"가격" : discount,
"ISBN" : isbn
}, columns = ["제목", "저자", "출판사", "출판일", "가격", "ISBN" ])
return result제목, 저자, 출판사, 출판일, 가격, ISBN을 데이터 프레임으로 저장해주는 함수입니다.
import time
def giveBookInfo(datas , name, start, end):
for n in range(start, end, 100):
url = giveme_url("book", name, n, 100 )
book_result = giveme_code(url)
result = save_info(book_result)
if len(result) == 0:
print("데이터 수집이 종료되었습니다.")
break
datas.append(result)
time.sleep(1)그러면 이제 네이버 API를 사용해야죠. url을 만들어서 넣고, 코드를 가져오는 과정을 for문을 돌리게 됩니다.
(네이버 API는 한번에 1000개의 정보를 가져올 수 있어서 n을 1000으로 고정하는게 맞다고 봅니다.)
book 사이트에서 name 키워드로 검색해서 n페이지의 100개씩 들고오세요의 일을 하는 코드입니다.
(강의실의 와이파이가 안좋아서 time.sleep으로 1초간 쉬게 만들었습니다. 집에서 할때는 굳이 필요없다는 생각이드네요.)
그러면 자료를 가져와서 저장을 해야겠죠?
print("파이썬 시작!!")
python_datas = []
giveBookInfo(python_datas , "파이썬", 1, 1000)
giveBookInfo(python_datas , "python", 1, 1000)
python = pd.concat(python_datas)
python.to_csv(
"python.csv", sep=',', encoding="UTF-8"
)
# 파이썬, python을 검색해서 1000개의 정보를 가져와서
# python_datas에 저장해주세요. 그걸 csv 파일로 저장합니다.
# 밑의 코드도 이와 동일합니다.
print("씨 시작!!")
c_data = []
giveBookInfo(c_data, "C언어", 1, 1000)
giveBookInfo(c_data, "C language", 1, 1000)
C_LANGUAGE = pd.concat(c_data)
C_LANGUAGE.to_csv(
"c.csv", sep=',', encoding="UTF-8"
)
print("씨피피 시작!!")
cpp_data = []
giveBookInfo(cpp_data, "C++", 1, 1000)
Cpp = pd.concat(cpp_data)
Cpp.to_csv(
"c++.csv", sep=',', encoding="UTF-8"
)
print("씨썁 시작!!")
c_shop_data = []
giveBookInfo(c_shop_data, "C#", 1, 1000)
Cshop = pd.concat(c_shop_data)
Cshop.to_csv(
"C#.csv", sep=',', encoding="UTF-8"
)
print("자바 시작!!")
java_data = []
giveBookInfo(java_data, "자바", 1, 1000)
giveBookInfo(java_data, "java", 1, 1000)
java = pd.concat(java_data)
java.to_csv(
"java.csv", sep=',', encoding="UTF-8"
)
print("자바스크립트 시작!!")
java_script_data = []
giveBookInfo(java_script_data, "자바스크립트", 1, 1000)
giveBookInfo(java_script_data, "javascipt", 1, 1000)
javascript = pd.concat(java_script_data)
javascript.to_csv(
"javascipt.csv", sep=',', encoding="UTF-8"
)
print("비베 시작!!")
visualbasic_data = []
giveBookInfo(visualbasic_data, "비쥬얼베이직", 1, 1000)
giveBookInfo(visualbasic_data, "visual basic", 1, 1000)
visualbasic = pd.concat(visualbasic_data)
visualbasic.to_csv(
"비쥬얼베이직.csv", sep=',', encoding="UTF-8"
)
print("에스큐엘 시작!!")
SQL_DATA = []
giveBookInfo(SQL_DATA, "SQL", 1, 1000)
SQL = pd.concat(SQL_DATA)
SQL.to_csv(
"SQL.csv", sep=',', encoding="UTF-8"
)
print("피에이치피 시작!!")
PHP_data = []
giveBookInfo(PHP_data, "PHP", 1, 1000)
PHP = pd.concat(PHP_data)
PHP.to_csv(
"PHP.csv", sep=',', encoding="UTF-8"
)
print("R언어 시작!!")
R_data = []
giveBookInfo(R_data, "R언어", 1, 1000)
R_language = pd.concat(R_data)
R_language.to_csv(
"R.csv", sep=',', encoding="UTF-8"
)
print("끝!!")다음 코드를 실행하면 제한량이 70~100씩 까이는데
걱정안해도 됩니다. 하루 제한량은 25000인가 그렇습니다.

그러면 성공적으로 저장이 된 것이구요. 폴더를 확인해보면
파일들이 생성된 것을 확인할 수 있었습니다.
확인차 3번 돌렸는데 280번..
여기까지 따라오셨다면
데이터를 백업하시고
새로운 ipynb 파일을 만들어주세요.
데이터 전처리를 진행해야하는데, 데이터 오류가 나면
백업된 파일로 다시 넣어주셔야합니다.
(불러오는 시간이 너무 길기도 하고, 하루 할당량 제한이 있으니까요.)
문제2) ISBN넘버를 통해 중복데이터를 정리하세요.
C언어 csv에는 C++, C#이 들어갈 수도 있고, 자바 csv에는 자바스크립트가 들어갈 수 있다.
- 그 외에는 중복행을 제거하는 drop_duplicates()를 통해 가공하고 다시 저장하자.
import pandas as pd
C_data = pd.read_csv("./c.csv", index_col = 0 )
C_data.info()
C 파일에는 C++, C#이 있을 수 있으니까 정말 지우는지 확인해봅시다.
C_data = C_data[~C_data['제목'].str.contains('C\+\+')]
C_data = C_data[~C_data['제목'].str.contains('C\#')]
C_data.info()
제목에 C++이 들어있거나 C#이 들어간 행을 제거합니다.
+의 경우 +만 넣으면 컴파일이 안됩니다. 그러니 \+ 로 입력해야하더군요.
약 200개의 데이터가 지워졌으니 의미없는 행동은 아니였습니다.
java_data = pd.read_csv("./java.csv", index_col = 0 )
java_data.info()
자바도 한 번 봅시다.
java_data = java_data[~java_data['제목'].str.contains('자바스크립트')]
java_data = java_data[~java_data['제목'].str.contains('Javascript')]
java_data = java_data[~java_data['제목'].str.contains('javascript')]
java_data.drop_duplicates()
java_data.info()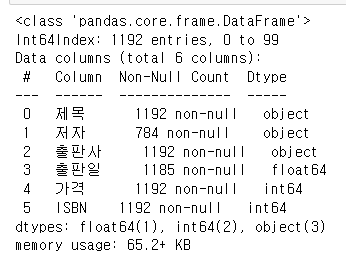
c언어 책의 개수는 다음과 같다.

ISBN정보로 중복 데이터를 정리하겠습니다.
- unnique() : 고유한 value는 몇개가 있는지 체크합니다.
- value_counts() 중복되는 value는 몇개가 있는지 확인해줍니다.
C_data['ISBN'].nunique()
고유한게 555개면 행의 수가 558개인 것은 문제가 있다.
C_data['ISBN'].value_counts()
ISBN이 겹치는 행이 3개 있다. 이를 지워야한다.
C_data = C_data.drop_duplicates(['ISBN'])
C_data['ISBN'].value_counts()ISBN 컬럼을 기준으로 중복자료를 지워버려라.

정상적으로 중복자료가 제거되었다.
- 검증이 끝났으니 모든 파일의 중복행을 제거하자 그리고 새로 저장하자.
- c언어와 자바는 빼고 가도록 하자.
C_shop_data = pd.read_csv("./C#.csv", index_col = 0 ).drop_duplicates(['ISBN'])
C_shop_data.to_csv(
"C#.csv", sep=',', encoding="UTF-8"
)
print("C샵 저장")
Cpp_data = pd.read_csv("./c++.csv", index_col = 0 ).drop_duplicates(['ISBN'])
Cpp_data.to_csv(
"c++.csv", sep=',', encoding="UTF-8"
)
print("C++ 저장")
javascipt_data = pd.read_csv("./javascipt.csv", index_col = 0 ).drop_duplicates(['ISBN'])
javascipt_data.to_csv(
"javascipt.csv", sep=',', encoding="UTF-8"
)
print("자바스크립트 저장")
PHP_data = pd.read_csv("./PHP.csv", index_col = 0 ).drop_duplicates(['ISBN'])
PHP_data.to_csv(
"PHP.csv", sep=',', encoding="UTF-8"
)
print("PHP 저장")
python_data = pd.read_csv("./python.csv", index_col = 0 ).drop_duplicates(['ISBN'])
python_data.to_csv(
"python.csv", sep=',', encoding="UTF-8"
)
print("파이썬 저장")
SQL_data = pd.read_csv("./SQL.csv", index_col = 0 ).drop_duplicates(['ISBN'])
SQL_data.to_csv(
"SQL.csv", sep=',', encoding="UTF-8"
)
print("SQL 저장")
visualBasic_data = pd.read_csv("./비쥬얼베이직.csv", index_col = 0 ).drop_duplicates(['ISBN'])
visualBasic_data.to_csv(
"비쥬얼베이직.csv", sep=',', encoding="UTF-8"
)
print("비쥬얼베이직 저장")
R_data = pd.read_csv("./R.csv", index_col = 0 ).drop_duplicates(['ISBN'])
R_data.to_csv(
"R.csv", sep=',', encoding="UTF-8"
)
print("R언어 저장")
print("저장 끝")for문으로 구현하고 싶었는데, 파일명이 계속 바뀌는 것때문에 일단 포기하고 노가다를 했다.
이걸 for문으로 만들 수 있는 레벨까지 파이썬 능력을 기르겠다.
이러면 데이터 전처리 과정은 끝나고 문제2번도 해결된다.
이 부분은 재시작하게 되면 결과값이 달라지니 새로운 ipynb를 만들도록하자.
import numpy as np
import pandas as pd
C_data = pd.read_csv("./c.csv", index_col = 0 )
java_data = pd.read_csv("./java.csv", index_col = 0 )
C_shop_data = pd.read_csv("./C#.csv", index_col = 0 )
Cpp_data = pd.read_csv("./c++.csv", index_col = 0 )
javascipt_data = pd.read_csv("./javascipt.csv", index_col = 0 )
PHP_data = pd.read_csv("./PHP.csv", index_col = 0 )
python_data = pd.read_csv("./python.csv", index_col = 0 )
SQL_data = pd.read_csv("./SQL.csv", index_col = 0 )
visualBasic_data = pd.read_csv("./비쥬얼베이직.csv", index_col = 0 )
새로운 ipynb를 만들었으니 다시 불러왔다.
문제3 각 언어별 출판물의 양으로 순위를 매겨주세요. 적절한 시각화를 사용하세요.
language_name = [
"C", "C#", "C++", "Python", "java",
"javascript", "PHP", "SQL", "visualBasic", "R"
]
language_book_sum = [
len(C_data), len(C_shop_data), len(Cpp_data), len(python_data), len(java_data),
len(javascipt_data), len(PHP_data), len(SQL_data), len(visualBasic_data) , len(R_data)
]
language_book_sum_df = pd.DataFrame({"언어":language_name, "총합":language_book_sum})
language_book_sum_df = language_book_sum_df.sort_values(by='총합' ,ascending=False)
# language_book_sum_df.set_index("언어", inplace=True)
language_book_sum_df
우선 언어의 이름을 가지는 리스트를 선언하고
언어별 책들의 총합을 가지는 리스트를 선언하자.
(내가 한 방법으로 하려면 둘의 순서가 같게 선언해야한다)
이를 데이터 프레임으로 만들고, 내림차순으로 정렬했다.
시각화를 진행하자
# matplotlib의 경우 한글폰트 깨짐현상을 방지하기 위한 코드
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
f_path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)
import seaborn as sns만약 우분투 환경이라면 코드가 달라진다. 맥 환경이라면 코드가 달라진다.
윈도우용 matplotlib의 한글 폰트 깨짐현상을 방지하기 위한 코드이다.
plt.subplots(figsize=(15,6))
sns.barplot(
language_book_sum_df['언어'].values[ :10],
language_book_sum_df['총합'].values[ : 10]
)
plt.xticks(rotation=90)
plt.title('언어별 발행된 책의 총 개수 비교')
plt.show()
언어별로 발행된 자료를 위의 그래프 형태로 보여주는 코드였다.
결론
- 파이썬과 자바가 가장 많았으며, 한가지 주목할만한 점은 SQL과 PHP가 프로그래밍의 기본 중에 하나인 C와 C++보다 많다는 점이다.
문제4 수집된 정보를 기반으로 우리나라의 컴퓨터 언어 관련 출판사 순위를 확인해 주세요.
- concat으로 데이터를 이어붙인다
- 혹시 모르니 ISBN이 중복되는 책이 있는지 확인해보자.
- value count를 활용해서 출판사로 정렬하자.
- 그리고 시각화를 진행하자.
language_book_publisher = pd.concat([C_data, java_data, C_shop_data, Cpp_data,
javascipt_data, PHP_data, python_data,
SQL_data, visualBasic_data, R_data ])
language_book_publisher모든 데이터 프레임을 하나로 이어붙였다.

혹시 모르니까 이상태에서도 중복되는 자료가 없는지 ISBN을 한 번 검사하자.
language_book_publisher.drop_duplicates(['ISBN']).fillna("")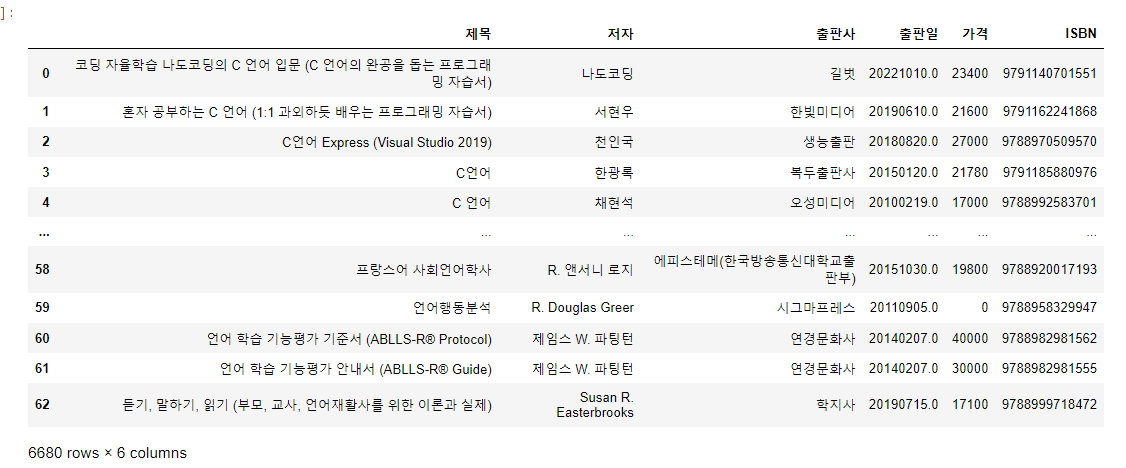
처음에 할 때는 설마 지워지는게 있겠어? 였는데, 자료가 200개나 삭제되길래 놀랐다.
책에 그런게 있었다. 제목에 C, C++ 등등 언어가 여러번 들어간 경우가 있더라.
- 데이터가 700개 가량 줄어들었다,. 그 이유가 뭘까?
- 데이터를 열어보면 책이름에 언어의 이름이 여러가지로 들어간 경우가 있다.
- 지우기를 잘한듯
- 우선 여기까지 진행한 정보를 저장하자.
language_book_publisher.to_csv(
"데이터총합.csv", sep=',', encoding="UTF-8"
)
language_book_publisher["출판사"].value_counts()
- 약 800 곳의 출판사가 존재한다. 우리는 상위 10곳의 출판사만 확인해보도록하자
plt.subplots(figsize=(15,6))
sns.barplot(
language_book_publisher['출판사'].value_counts().index[ :20],
language_book_publisher['출판사'].value_counts().values[ : 20]
)
plt.xticks(rotation=90)
plt.title('프로그래밍 책을 가장 많이 출판한 상위 20곳의 출판사')
plt.show()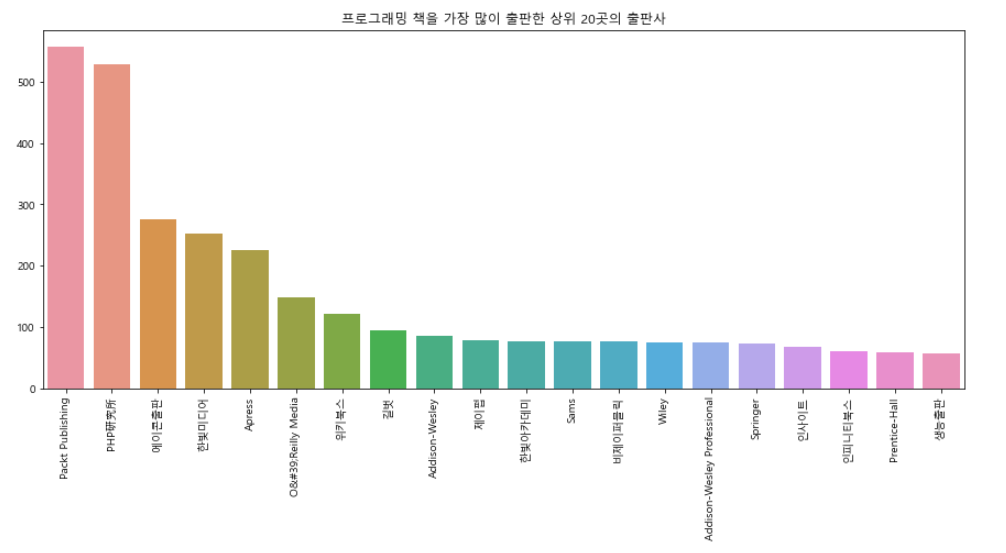
- Parket Publishing의 경우 IT를 전문적으로 다루고 있으며, 해외출판사이고, 대부분 직수입책이다.
- PHP연구소는 일본의 출판사
- 우리나라 출판사 중에서는 에이콘출판사와 한빛미디어가 가장 많은 it책을 만들었다.
문제 4. 수집된 정보를 보면 우리나라 컴퓨터 관련 출판사의 순위를 확인해주세요.
- 이 문제는 검색으로 확인해야할 것 같다.
- 외국출판사는 한글을 가지지 않는다. 이거로 전처리를 하면 영어로만된 한국 출판사가 제외될 수 있기 때문
- 상위 10개 출판사까지 알아보자.
language_book_publisher["출판사"].value_counts().head(20)
- 1위 : 에이콘출판사
- 2위 : 한빛미디어
- 3위 : 위키북스
- 4위 : 길벗
- 5위 : 한빛아카데미
- 6위 : 제이펍
- 7위 : 인사이트
- 8위 : 비제이퍼블릭
- 9위 : 성안당
- 10위 : 인피니티북스
문제5 수집된 정보에서 최근 2년간(20년, 21년)데이터와 그 전 (17년, 18년, 19년) 데이터를 비교해주세요.
-> 위의 사이트는 왜 넣어놓았지 로딩도 안되는데, 뭔가 정보를 얻은거 같습니다.
우리의 목적은 위에 출판일에서 연도만 뽑아내서 연도열을 저장하는 것입니다.
근데, 한가지 눈에 들어온건 왜 .0 로 표현이 되는가?
혹시나 해서 어떤 변수형인지 확인을 해봤습니다.
language_book_publisher.head()
language_book_publisher.info()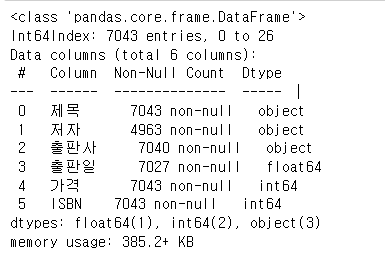
float형이더군요, 그래서 이를 string으로 바꿔주고 앞에 글자만 뽑아내자고 생각을 했습니다.
language_book_publisher['출판일'] = language_book_publisher['출판일'].astype(str)
language_book_publisher.info()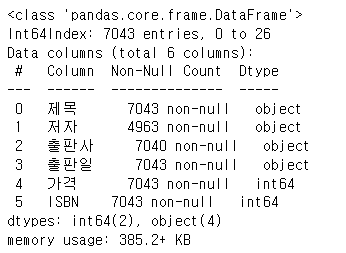
language_book_publisher.head()
뭐 그대로긴 해도 뭔가 info에서 object형이 되었으니 바뀌긴 했습니다.
language_book_publisher["연도"] = language_book_publisher["출판일"].str[:4]
language_book_publisher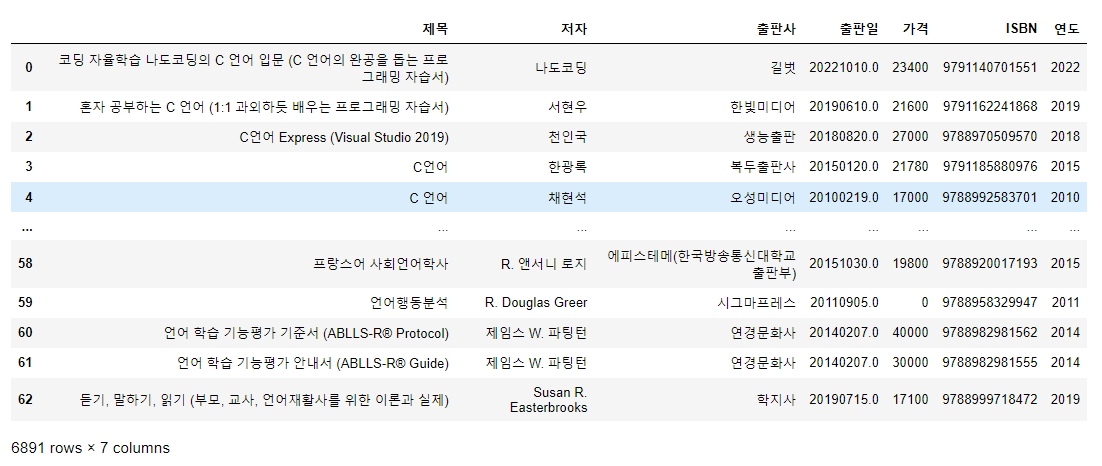
20221010.0 에서 앞에 4개만을 잘라서 연도 컬럼을 만들어서 저장하세요.
- 데이터를 분리하는 연습을 해보면서 어떠한 작업을 할 수 있을지 고민했다.
- 문제에서 원하는 것은 언어의 트랜드가 어디로 이동했는가이다.
- 그러니 각 언어별로 연도열을 생성하고, 20,21년과 17,18,19년을 비교하자
그러면 연도 데이터를 얻었습니다. 여기서 부터 문제가 생겼습니다. 각 언어별로 연도를 생성하고 17~21년을 분리해내야한다고 생각을 했습니다.
그러나 for문을 연구했지만 결국 안되더군요 (한 2~3시간 고민하고 결국 포기하고 노가다를 했습니다.)
language = [C_data, java_data, C_shop_data, Cpp_data,
javascipt_data, PHP_data, python_data,
SQL_data, visualBasic_data, R_data ]
for each in language:
each['출판일'] = each['출판일'].astype(str)
each["연도"] = each["출판일"].str[:4]
each["개수"] = 1일단 그래도 한가지 성공적으로 구현한건 for문으로 각 언어 자료에서 연도 컬럼을 생성하는 것에는 성공했습니다.
개수컬럼을 만들었는데 그 이유는 밑에서 설명하겠습니다.
그러나 다음에 보시는 코드가 문제였죠.
C_data_pivot = C_data.pivot_table(C_data, index=["연도"], aggfunc = [np.sum] )
C_data_pivot.columns = ['/'.join(col) for col in C_data_pivot.columns]
del C_data_pivot["sum/가격"]
del C_data_pivot["sum/ISBN"]
C_data_pivot.rename(columns={C_data_pivot.columns[0]: "C언어"}, inplace=True)
C_data_pivot = C_data_pivot.tail(7)
C_data_pivot = C_data_pivot.drop(["2016", "2022"])
C_data_pivot
우선 연도를 기준으로 np.sum으로 피벗을 하면 정수형 value가 있는 컬럼은 모두가 sum()됩니다. 그래서
개수 컬럼 = 1로 추가하고 피벗을 돌리면 2017년 연도의 개수=1들이 다 더해집니다.
(말로 설명하기 어려운데, 위에서 개수 컬럼없이 만들어보고 개수컬럼 있게 만들어보면 이해가 되실겁니다.)
그리고 피벗을 하면 컬럼 이름이 sum/가격 으로 변경되니 그 컬럼들을 모두없애고
sum/개수 컬럼의 이름을 C언어로 변경하고
끝에 있는 자료 7개를 출력해보고
2022년과 2016년도 데이터를 지웠습니다.
(이 부분은 직접 보고 손수 없애줘야 했습니다.)
일단 나머지 작업들의 코드들을 올릴게요. (길어요.
java_data_pivot = java_data.pivot_table(java_data, index=["연도"], aggfunc = [np.sum] )
java_data_pivot.columns = ['/'.join(col) for col in java_data_pivot.columns]
del java_data_pivot["sum/가격"]
del java_data_pivot["sum/ISBN"]
java_data_pivot.rename(columns={java_data_pivot.columns[0]: "java"}, inplace=True)
java_data_pivot = java_data_pivot.tail(7)
java_data_pivot = java_data_pivot.drop(["nan", "2022"])
java_data_pivot
C_shop_data_pivot = C_shop_data.pivot_table(C_shop_data, index=["연도"], aggfunc = [np.sum] )
C_shop_data_pivot.columns = ['/'.join(col) for col in C_shop_data_pivot.columns]
del C_shop_data_pivot["sum/가격"]
del C_shop_data_pivot["sum/ISBN"]
C_shop_data_pivot.rename(columns={C_shop_data_pivot.columns[0]: "C#"}, inplace=True)
C_shop_data_pivot = C_shop_data_pivot.tail(7)
C_shop_data_pivot = C_shop_data_pivot.drop(["nan", "2022"])
C_shop_data_pivot
Cpp_data_pivot = Cpp_data.pivot_table(Cpp_data, index=["연도"], aggfunc = [np.sum] )
Cpp_data_pivot.columns = ['/'.join(col) for col in Cpp_data_pivot.columns]
del Cpp_data_pivot["sum/가격"]
del Cpp_data_pivot["sum/ISBN"]
Cpp_data_pivot.rename(columns={Cpp_data_pivot.columns[0]: "C++"}, inplace=True)
Cpp_data_pivot = Cpp_data_pivot.tail(7)
Cpp_data_pivot = Cpp_data_pivot.drop(["nan", "2022"])
Cpp_data_pivot
javascipt_data_pivot = javascipt_data.pivot_table(javascipt_data, index=["연도"], aggfunc = [np.sum] )
javascipt_data_pivot.columns = ['/'.join(col) for col in javascipt_data_pivot.columns]
del javascipt_data_pivot["sum/가격"]
del javascipt_data_pivot["sum/ISBN"]
javascipt_data_pivot.rename(columns={javascipt_data_pivot.columns[0]: "자바스크립트"}, inplace=True)
javascipt_data_pivot = javascipt_data_pivot.tail(6)
javascipt_data_pivot = javascipt_data_pivot.drop(["2022"])
javascipt_data_pivot
PHP_data_pivot = PHP_data.pivot_table(PHP_data, index=["연도"], aggfunc = [np.sum] )
PHP_data_pivot.columns = ['/'.join(col) for col in PHP_data_pivot.columns]
del PHP_data_pivot["sum/가격"]
del PHP_data_pivot["sum/ISBN"]
PHP_data_pivot.rename(columns={PHP_data_pivot.columns[0]: "PHP"}, inplace=True)
PHP_data_pivot = PHP_data_pivot.tail(6)
PHP_data_pivot = PHP_data_pivot.drop(["2022"])
PHP_data_pivot
python_data_pivot = python_data.pivot_table(python_data, index=["연도"], aggfunc = [np.sum] )
python_data_pivot.columns = ['/'.join(col) for col in python_data_pivot.columns]
del python_data_pivot["sum/가격"]
del python_data_pivot["sum/ISBN"]
python_data_pivot.rename(columns={python_data_pivot.columns[0]: "파이썬"}, inplace=True)
python_data_pivot = python_data_pivot.tail(8)
python_data_pivot = python_data_pivot.drop(["nan", "2022", "2023"])
python_data_pivot
SQL_data_pivot = C_data.pivot_table(SQL_data, index=["연도"], aggfunc = [np.sum] )
SQL_data_pivot.columns = ['/'.join(col) for col in SQL_data_pivot.columns]
del SQL_data_pivot["sum/가격"]
del SQL_data_pivot["sum/ISBN"]
SQL_data_pivot.rename(columns={SQL_data_pivot.columns[0]: "SQL"}, inplace=True)
SQL_data_pivot = SQL_data_pivot.tail(6)
SQL_data_pivot = SQL_data_pivot.drop(["2022"])
SQL_data_pivot
visualBasic_data_pivot = visualBasic_data.pivot_table(visualBasic_data, index=["연도"], aggfunc = [np.sum] )
visualBasic_data_pivot.columns = ['/'.join(col) for col in visualBasic_data_pivot.columns]
del visualBasic_data_pivot["sum/가격"]
del visualBasic_data_pivot["sum/ISBN"]
visualBasic_data_pivot.rename(columns={visualBasic_data_pivot.columns[0]: "visualBasic"}, inplace=True)
visualBasic_data_pivot = visualBasic_data_pivot.tail(6)
visualBasic_data_pivot = visualBasic_data_pivot.drop(["nan"])
visualBasic_data_pivot
R_data_pivot = R_data.pivot_table(R_data, index=["연도"], aggfunc = [np.sum] )
R_data_pivot.columns = ['/'.join(col) for col in R_data_pivot.columns]
del R_data_pivot["sum/가격"]
del R_data_pivot["sum/ISBN"]
R_data_pivot.rename(columns={R_data_pivot.columns[0]: "R언어"}, inplace=True)
R_data_pivot = R_data_pivot.tail(6)
R_data_pivot = R_data_pivot.drop(["2022"])
R_data_pivot정신나갈뻔 했습니다.
여튼 과제가 끝나고 강사님에게 질문하니 아마 for문이 안돌았다면, 처음 계획이 잘못되었을 가능성이 높다고 말씀해주셔서
정말 시간나면 재설계를 하면서 확 줄여볼 수 있는 방법을 고민해보겠습니다.
언어별 5년간 출간된 책들의 개수를 가지는 데이터를 얻었다.
- 이를 가지고 분석을 하도록하자
language_17_21 = pd.concat([C_data_pivot, java_data_pivot, C_shop_data_pivot, Cpp_data_pivot,
javascipt_data_pivot, PHP_data_pivot, python_data_pivot,
SQL_data_pivot, visualBasic_data_pivot, R_data_pivot], axis = 1)
language_17_21 = language_17_21.head(5).fillna(0)
language_17_21이 자료를 오른쪽으로 붙이면
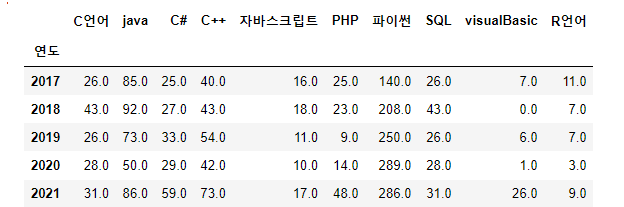
우리가 원하는 자료가 만들어졌습니다.
숫자는 그 해에 출판된 책의 개수 입니다.
language_17_21.to_csv(
"language_17_21.csv", sep=',', encoding="UTF-8"
)힘들었으니 저장해야죠.
language_17_19 = language_17_21.drop(["2020", "2021"])
language_17_1920년과 21년 자료를 드랍하면 17~19년만 남겠죠?

그 자료를 그대로 쓰면 20년, 21년은 2년이니 비교하기 어려우니 평균을 구하는게 좋다고 생각했습니다.
language_17_19_mean = pd.DataFrame(language_17_19.mean())
language_17_19_mean.rename(columns={language_17_19_mean.columns[0]: "평균"}, inplace=True)
language_17_19_mean = language_17_19_mean.sort_values(by='평균' ,ascending=False)
language_17_19_mean
평균값으로 다시 그래프를 그렸습니다.
이 과정을 20, 21년도 동일하게 진행합니다.
language_20_21 = language_17_21.drop(["2017", "2018", "2019"])
language_20_21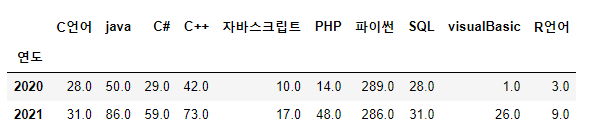
language_20_21_mean = pd.DataFrame(language_20_21.mean())
language_20_21_mean.rename(columns={language_20_21_mean.columns[0]: "평균"}, inplace=True)
language_20_21_mean = language_20_21_mean.sort_values(by='평균' ,ascending=False)
language_20_21_mean
이제 시각화를 진행하면 끝난다!
f, ax = plt.subplots(1,2, figsize=(20,6))
language_17_19_mean['평균'].plot.pie(ax= ax[0], autopct = "%.1f")
ax[0].set_title('17~19년 언어별 출간된 책 통계')
ax[0].set_ylabel('')
language_20_21_mean['평균'].plot.pie( ax= ax[1], autopct = "%.1f")
ax[1].set_title('20~21년 언어별 출간된 책 통계')
ax[1].set_ylabel('')
plt.show()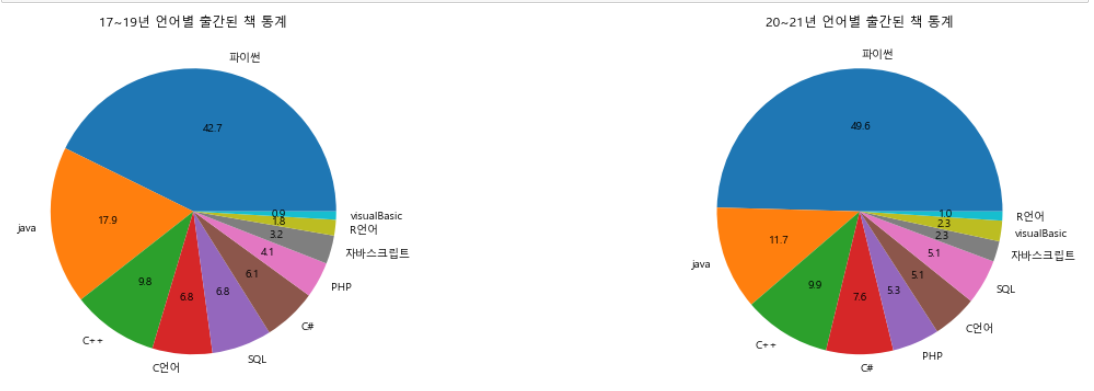
결론
- 파이썬의 비중이 20~21년 40%에서 약 50%정도로 늘어났다.
- 자바의 경우 17%에서 11.6%정도로 감소하였지만 여전히 2등이다.
- C언어와 C++의 자리가 바뀌었다.
- SQL의 순위가 3위에서 5위로 내려갔다.
힘들다.. 힘들어..