3. crawling을 통해 그래픽카드의 특가를 노려보자. (tistory.com)
3. crawling을 통해 그래픽카드의 특가를 노려보자.
들어가기전 pinkwink 강사님께서 수업자료와 관련되어 실습을 스스로 진행하여 블로그에 기술하는 것에 문제가 없다고 언급해주시어 오늘까지 나만의 프로젝트로 진행을 하고, 주말동안 강의자
kimbrain.tistory.com
이 글과 이어지나, 지금 포스트만 읽어도 따라할 수 있게 해보겠습니다.
서론은 위 글에 적어놓았으니
서론은 생략하고 바로 본론으로 들어가면
크롤링을 할 때

https://search.shopping.naver.com/search/all?query=RTX+3070&bt=-1&frm=NVSCPRO
1페이지에서 2페이지로 넘어가봅시다.
2페이지로 넘어가면 pagingindex = 2 로 변경된 것이 보일 것입니다.
3페이지로 넘어가면 pagingindex = 3 으로 변경된 것이 보입니다.
그러면 이렇게 생각할 수 있습니다.
for문으로 paingindex = i
에다가 i 를 2~100까지 넣어버리면 100페이지의 정보를 뽑아올 수 있네?
결론은
가능합니다.
그러나
여러분의 IP가 네이버측에 의해 차단될 수 있습니다.
크롤링을 할 때 서버에 부담을 주기 때문에 차단해버리는 것입니다.
그래서 네이버측에서 크롤링을 하고 싶으면, 우리가 제공하는 것을 사용해라.
대신 하루에 크롤링할 수 있는 양을 제한하겠다.
하고 나온 것이 네이버 API입니다.
해당 포스트는

현. 제로베이스 데이터 사이언스 강사님이신 조용하 강사님의
강의자료를 참고하여 제작되었습니다.
먼저 anaconda prompt 를 켜서
jupyter notebook 명령어로 jupyter notebook을 입력하여 실행합시다.

(물론 바로 jupyter notebook 아이콘을 눌러 실행할 수 있으나, 좀 있어 보이잖아요 ㅎㅎ)
(가상환경을 변경할 수 있긴합니다. 만 그냥 실행합시다.)

일단 주피터노트북은 준비가 끝났습니다.
이제 검색창에 "네이버 개발자 모드" 를 검색합시다.
대충 로그인 하시구요.

Application -> 애플리케이션 등록을 들어갑니다.

쓰고싶은거 사용하시면 되는데
검색, 데이터랩(검색어트랜드), 데이터랩(쇼핑인사이트)를 설정하세요

비로인인 오픈 API 서비스 환경은 WEB으로 설정하겠습니다.

URL에는 http://localhost 를 입력합니다.

그러면 Client ID와 Client Secret이 나옵니다.
이게 여러분에게 할당된 ID와 비밀번호입니다. 이를 메모장에 복사해놓으시구요.
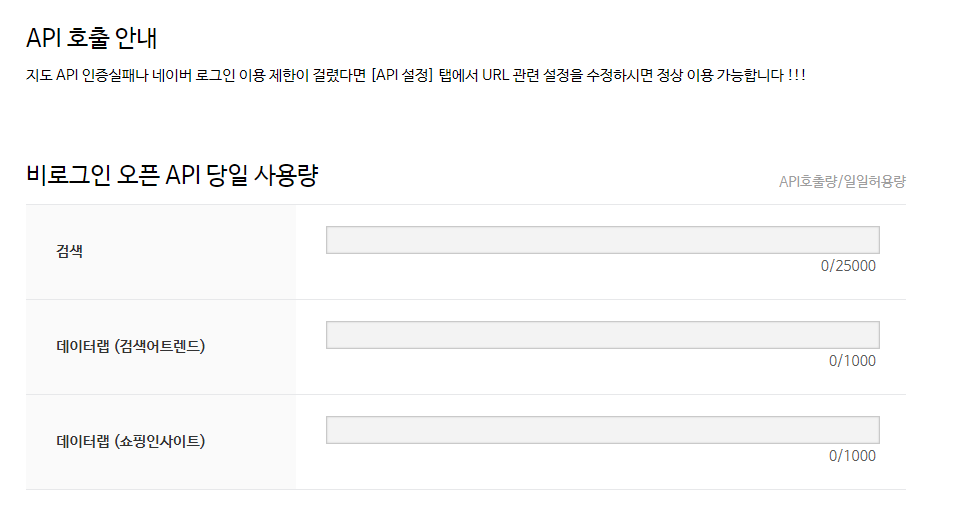
이게 여러분에게 할당된 양(?)입니다.
이를 넘기면 더 이상 사용을 할 수 없습니다.

Documents 에서 서비스 API의 검색을 들어갑니다.

우리는 파이썬을 사용하니 Python을 누르면 해당 소스코드가 나옵니다.
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
encText = urllib.parse.quote("검색할 단어")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
이제 네이버API 준비도 끝났습니다.
이제 쥬피터 노트북으로 돌아갑시다.
해당 소스코드를 복사 하고 붙여넣기합니다.
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
# request는 url의 코드를 가져온다 생각하면 됩니다.
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
# 방금 발급 받은 ID와 SECRET을 여기에 넣으세요.
encText = urllib.parse.quote("검색할 단어")
# 검색할 단어에 검색하고 싶은 것을 넣으세요.
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
# 그러면 검색어를 Url에 넣고
request = urllib.request.Request(url)
# URL의 코드를 주세요.
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
# 접근권한이 있어요. 내 아이디와 비밀번호를 보세요.
response = urllib.request.urlopen(request)
# 네이버에서 응답을 해서 자료를 제공해준다.
rescode = response.getcode()
# 코드를 recode에 넣을게요.
if(rescode==200):
# 잘 받았다면 200을 return 하게됩니다.
response_body = response.read()
# 읽어들은 결과를
print(response_body.decode('utf-8'))
# 출력합니다.
else:
print("Error Code:" + rescode)
그러면 한 번 예시를 보일까요?
검색어는 "맥도날드 치즈버거" 로 할까요?


이런식으로 결과가 나오게 됩니다.
뉴스를 검색하고 싶으면
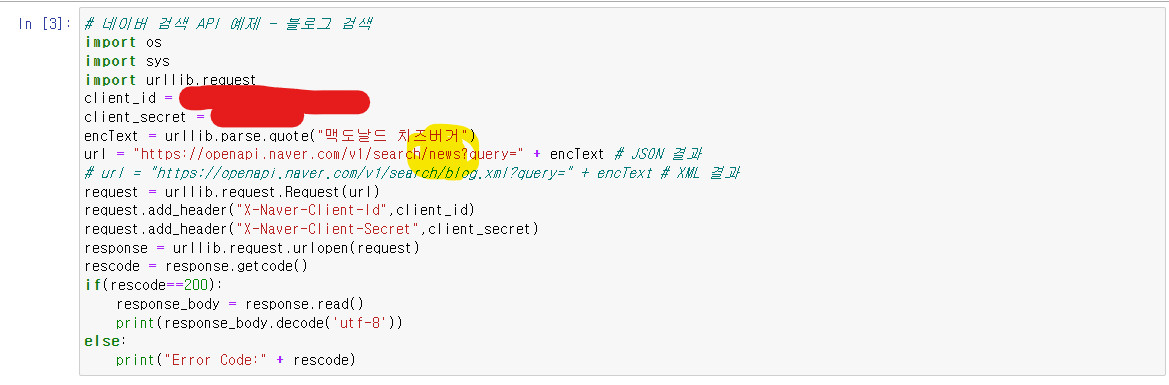
노란 형광펜 부분을 news로 고쳐주시면 됩니다.

쇼핑이면?


간단하죠?
그럼 이상태에서 바로 전처리를 진행하면 됩니다
자 이제.. 본론으로 들어가서 그래픽카드 특가 크롤링을 시작해봅시다.
우리의 목표는
url의 1~100페이지까지 그래픽카드 쇼핑몰 정보를 긁어오고 싶다.
목표를 해결하기 위해서
- url을 만들어주는 함수가 필요합니다.
- 쇼핑물 정보를 긁어야 하니까 url에 "shop"이 추가되어야 합니다.
- "검색어"를 가지는 url이 필요합니다.
- url의 x페이지에 y개를 보여주세요.
2.구현
- 함수가 받아와야 하는 값은 shop, 검색어, x, y가 필요합니다
- giveme_url(shop, 검색어, x, y) 의 함수를 만들어 봅시다.
"https://openapi.naver.com/v1/search/shop?query=""&start = &display=
코드를 분석해봅시다.
https://openapi.naver.com/v1/search/ + type + ?query=" 검색어 + "&start= + 문자열(x) + &display= + 문자열(y)
함수가 어떻게 동작해야할지 감이 오시나요?
type, 검색어, x, y를 입력받고 저 주소에다가 끼워넣고 return 하면 됩니다.
def giveme_url(site_type, search, start_num, show_num ):
return "https://openapi.naver.com/v1/search/" + site_type + '?query="' + search + '"&start=' + str(start_num) + "&display=" + str(show_num)어.. 가독성이 별로라 수정좀 하겠습니다.
def giveme_url(site_type, search, start_num, show_num ):
site = "https://openapi.naver.com/v1/search/" + site_type + '?query="' + \
search + '"&start=' + str(start_num) + "&display=" + str(show_num)
return site\는 줄바꿈을 나타냅니다.

그러면 url을 정상적으로 받아오는 것을 확인할 수 있었습니다.
그러면 url을 받아왔습니다. 그 다음은 url의 코드를 받아와야 합니다.
아까 예시의 코드를 다시 한 번 확인합시다.
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
# request는 url의 코드를 가져온다 생각하면 됩니다.
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_SECRET"
# 방금 발급 받은 ID와 SECRET을 여기에 넣으세요.
encText = urllib.parse.quote("검색할 단어")
# 검색할 단어에 검색하고 싶은 것을 넣으세요.
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
# 그러면 검색어를 Url에 넣고
request = urllib.request.Request(url)
# URL의 코드를 주세요.
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
# 접근권한이 있어요. 내 아이디와 비밀번호를 보세요.
response = urllib.request.urlopen(request)
# 네이버에서 응답을 해서 자료를 제공해준다.
rescode = response.getcode()
# 코드를 recode에 넣을게요.
if(rescode==200):
# 잘 받았다면 200을 return 하게됩니다.
response_body = response.read()
# 읽어들은 결과를
print(response_body.decode('utf-8'))
# 출력합니다.
else:
print("Error Code:" + rescode)이제 남은 것은 ID와 비밀번호를 넣고
코드를 뽑아내야하는 것입니다.
밑의 부분만 분리해서 보면
우리가 수행해야할 이번 목표는 밑의 코드를 함수화 시키는 것입니다.

여기서 json을 통해 받아낸 자료의 자료형을 수정을 하면됩니다.
- url의 코드를 뽑아내고 싶습니다.
- id와 비밀번호를 입력받고
- url의 코드를 받아옵시다.
- def giveme_code(url)
import json
def giveme_code(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request)
print("페이지를 불러왔습니다.")
return json.loads(response.read().decode("utf-8"))
url = giveme_url("shop", "치즈버거", 1, 3)
code = giveme_code(url)
code위의 4줄은 예제에서 가져왔습니다.

UnicodeEncodeError: 'ascii' codec can't encode characters in position 27-30: ordinal not in range(128)해당 오류가 발생한다.
이유가 무엇일까??
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_target = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_target + param_disp
# 내 코드
def giveme_url(site_type, search, start_num, show_num ):
site = "https://openapi.naver.com/v1/search/" + site_type + '?query="' + \
search + '"&start=' + str(start_num) + "&display=" + str(show_num)
return site
내 코드는 위의 코드를 간략화하였다.
예제의 결과는
'https://openapi.naver.com/v1/search/shop.json?query=%EC%B9%98%EC%A6%88%EB%B2%84%EA%B1%B0&start=1&display=3'내 코드의 결과는
'https://openapi.naver.com/v1/search/shop?query="치즈버거"&start=1&display=3'이렇게 생겼다.
비교를 해보니 어떤 처리과정이 더 진행되었다.
해당 오류는 한국어로 크롤링시 자주 발생하는 오류라고 한다.
내 코드를
def giveme_url(site_type, search, start_num, show_num ):
site = "https://openapi.naver.com/v1/search/" + site_type + '?query="' + \
urllib.parse.quote(search) + '"&start=' + str(start_num) + "&display=" + str(show_num)
return site다음과 같이 수정하였다.
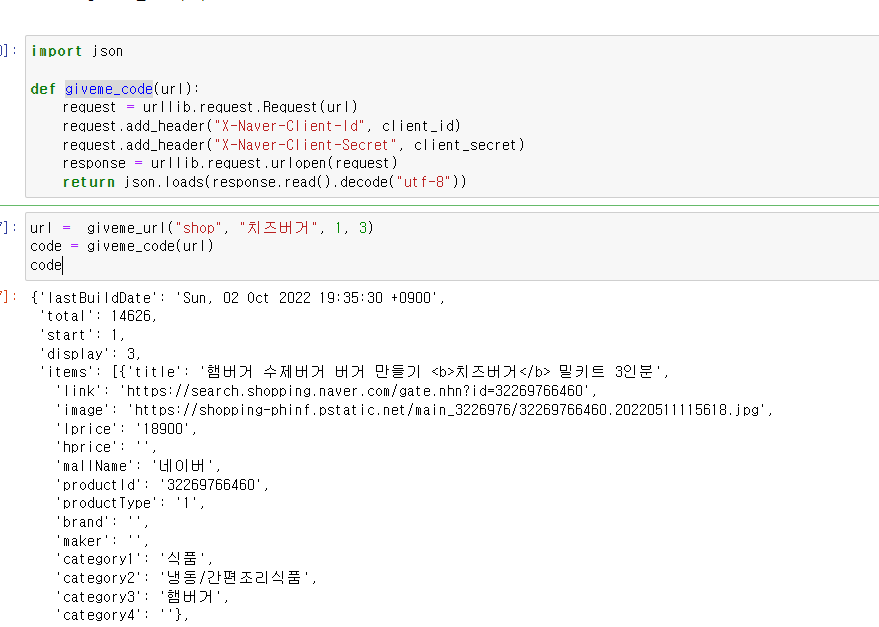
오류없이 잘 작동하는 것을 확인하였다.
우리가 원하는 정보는 그래픽카드의 특가를 잡는 것이다.
이번에는 3070말고, RTX3050으로 해보는게 어떨까?
(단일상품이라 다른 상품이 나올 확률이 없기 때문)
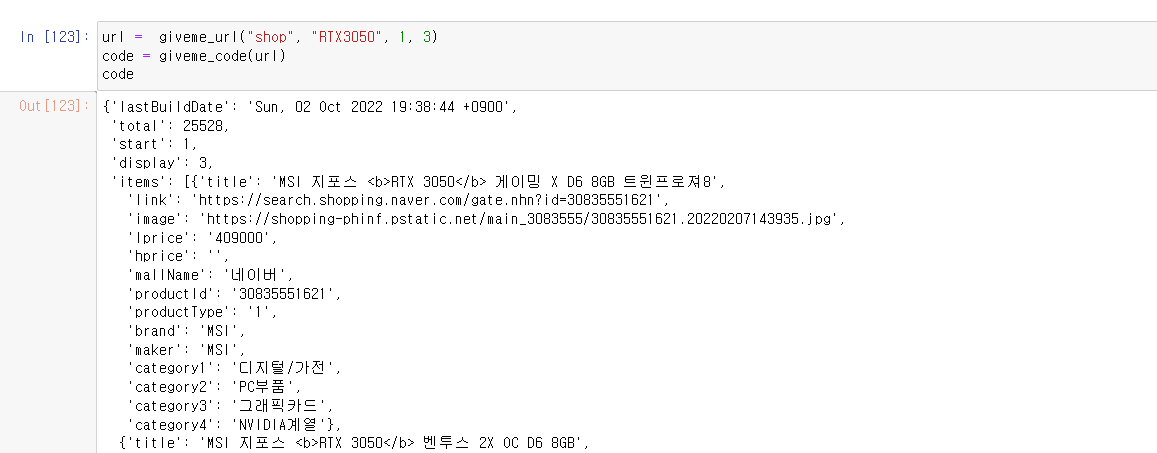
3. 데이터 전처리하여 저장하는 함수를 작성해보자.
- 제목, 가격, 판매자, 링크를 변수로 생성하여 append를 사용해서 변수에 계속해서 추가해나가면 우리가 원하는 정보를 얻을 수 있다.
이제 데이터를 전처리하는 과정을 보자.
위의 코드에서 보면 알겠지만.
items 항목에 title이 이름, lprice가 가격, mallName이 판매자이다.
그러니

이런식으로 정보를 뽑아낼 수 있다.
제목에 문제는 <b>가 포함된다는 것이다. 이를 삭제하는 함수를 만들자.
def del_b(str):
str = str.replace("<b>", "")
str = str.replace("</b>", "")
return strtitle = del_b(code['items'][0]["title"])
title

이제 데이터를 저장해보자.
import pandas as pd
def save_info(data):
title = del_b(data['items'][0]["title"])
price = data['items'][0]["lprice"]
link = data['items'][0]["link"]
mall = data['items'][0]["mallName"]
result = pd.DataFrame({
"title" : title,
"price" : price,
"link" : link,
"mall" : mall
}, columns = ["title", "price", "link", "mall" ])
return result위의 코드는 돌아가지 않는다.
(우선은 코드가 어떻게 돌아갈지 예상을 해보자는 의미이다.)
정보를 받아오고, 이를 결과에 저장하여 pandas를 활용해서 표로 만들어 보여주는 것이다.
그런데 그 정보를 가져오는 과정에서
예를 들어 title을 가져올 때
c언어를 배운 사람이라면 for을 돌려서 데이터를 입력받자 생각하지만 파이썬은 달랐다.
import pandas as pd
def save_info(data):
title = [del_b(each["title"]) for each in data["items"]]
link = [each["link"] for each in data["items"]]
price = [each["lprice"] for each in data["items"]]
mall_name = [each["mallName"] for each in data["items"]]
result = pd.DataFrame({
"제목" : title,
"가격" : price,
"링크" : link,
"판매자" : mall_name
}, columns = ["제목", "가격", "링크", "판매자" ])
return result데이터의 선언과 동시에 포문을 돌려버린다.
for문을
그림으로 설명해보면

data["item"] 의 리스트 개수만큼 (여기서는 3개가 되겠죠.)
리스트를 돌면서
title이 보이면 그 값을 저장하세요.

title을 먼저 리스트로 (C로하면 배열로)
싹 저장하고, link를 저장하고 이러는 방식으로 추측됩니다.
그리고 pandas를 통해서 표로 표시한 것이다.

여튼.. 결과는 이렇게 나온다.
이제 네이버 API의 힘을 볼 시간이다.
- 네이버 API의 한페이지당 100개씩 표시된다. 그러면 3050데이터 1000개를 가져온다면, 10page를 불러오면 된다.
result_datas = []
for n in range(1, 1000, 100):
url = giveme_url("shop", "RTX3050", n, 100 )
RTX_result = giveme_code(url)
result = save_info(RTX_result)
result_datas.append(result)
result_datas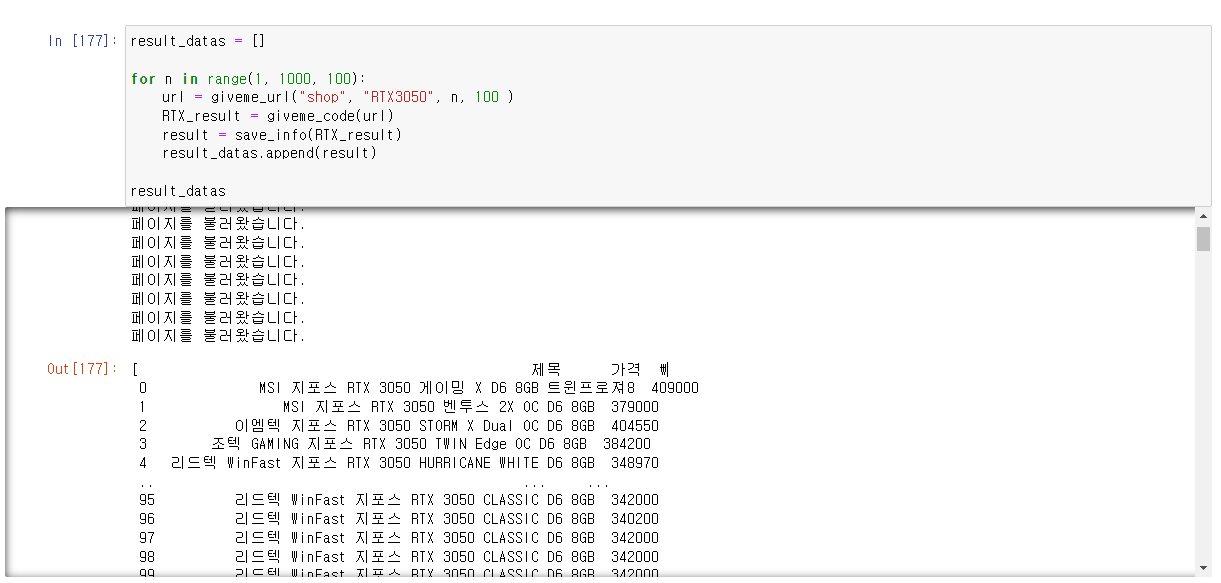
그러면 10페이가량의 RTX 3050 정보를 불러온다.

그러면 pandas를 이용해서 보자.
1000개의 데이터가 보일 것이다.
근데, 이상하다? 인덱스가 왜 999가 아니라 99인걸까?
이럴 때 인덱스를 리셋해야한다.
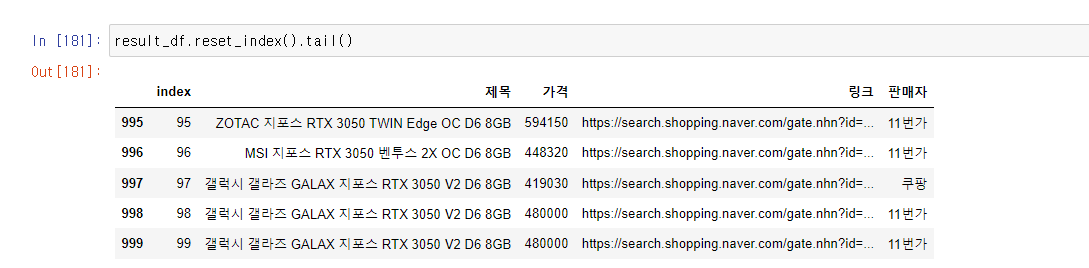
그리고 가격을 우리가 보기 편하게 하기 위해서 float형으로 변경해줘야한다.
result_df["가격"] = result_df["가격"].astype("float")(info로 확인해서 object 형일 경우 진행하면된다.)
이제 모든 데이터를 불러오는 기나긴 과정이 끝났다.
만약 이를 저장하고 싶다면
result_df.to_excel("RTX3050.xlsx", encoding="utf-8")해당 코드를 사용하면된다.

저장이 잘되었다. 자.. 이제활용해야지..
정보를 추출하자
내가 해보고 싶은건 제조사별로 모아보는 방법인데, 그렇게 하기 위해서는 크롤링의 범위를 벗어난다.
(판매자가 이름을 모두 동일하게 만든 것이 아니기 때문에 우리가 생각하는 느낌으로 깔끔하게 저장할 수는 없다.)
흐음? 할 수 있을것 같은데
아까 크롤링 했을 때, 제조사도 따로 표시되던 것을 확인했었다. 그러면 제조사를 끼고 다시 데이터를 뽑아보자.
import pandas as pd
def save_info(data):
title = [del_b(each["title"]) for each in data["items"]]
link = [each["link"] for each in data["items"]]
price = [each["lprice"] for each in data["items"]]
mall_name = [each["mallName"] for each in data["items"]]
maker = [each["maker"] for each in data["items"]]
result = pd.DataFrame({
"제목" : title,
"가격" : price,
"제조사" : maker
"링크" : link,
"판매자" : mall_name
}, columns = ["제목", "가격", "링크", "판매자" ])
return result해당 함수를 수정했다.
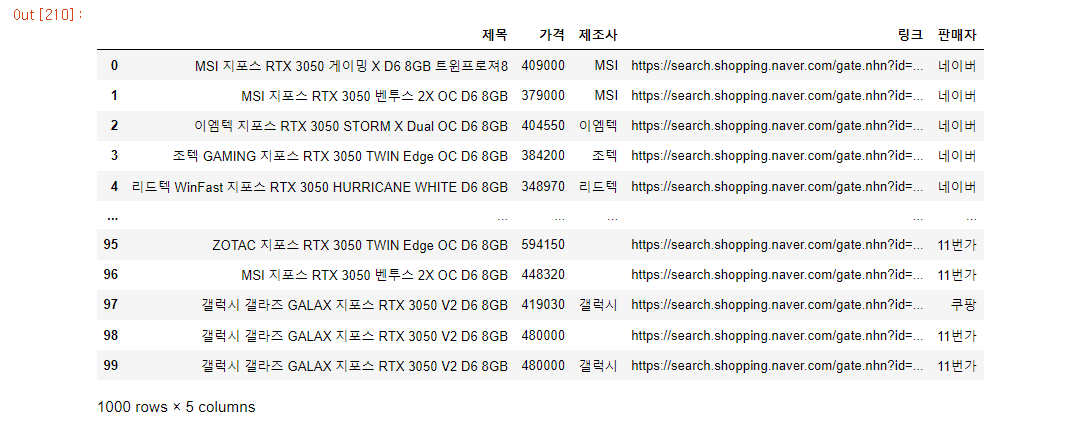
아.. 판매자가 제조사를 명시하지 않은 경우가 있다.
괜찮아 브랜드 카테고리도 있으니까
import pandas as pd
def save_info(data):
title = [del_b(each["title"]) for each in data["items"]]
link = [each["link"] for each in data["items"]]
price = [each["lprice"] for each in data["items"]]
mall_name = [each["mallName"] for each in data["items"]]
maker = [each["maker"] for each in data["items"]]
brand = [each["brand"] for each in data["items"]]
result = pd.DataFrame({
"제목" : title,
"가격" : price,
"제조사" : maker,
"브랜드" : brand,
"링크" : link,
"판매자" : mall_name
}, columns = ["제목", "가격", "제조사", "브랜드", "링크", "판매자" ])
return result제발 이번에는..

브랜드도 마찬가지네요.
데이터분석에 관한 이야기는 크롤링에 대한 이야기가 아니기도 하고
글이 엄청 길어져서 다음 글로 넘기도록 하겠습니다.
'취업전 프로젝트 > (Toy)_project' 카테고리의 다른 글
| 네이버 API를 이용해서 프로그래밍 언어책들을 조사해보자 (0) | 2022.10.17 |
|---|---|
| 네이버 API를 이용해서 그래픽카드 특가를 노려보자 (2/2) (0) | 2022.10.03 |
| 4. 세계 테러 데이터 분석하기 (0) | 2022.10.01 |
| crawling을 통해 그래픽카드의 특가를 노려보자. (0) | 2022.09.29 |
| 전기기사 자격증의 데이터를 분석해보자. (0) | 2022.09.27 |