
주의 : 이 글은 C의 기초문법에 대해 상세하게 다루지 않습니다. (즉 C언어에서 배울 수 있는 기초내용은 생략합니다)
※ 명품 C++ Programming 의 책을 참고하여 개인적으로 정리한 글입니다.
이 글의 목적은 해당 책의 내용을 인용하여 더 쉽게 이해하고자 정리하고, 더 쉬운 예제를 통해 이해하는 것을 목표로 하고 있습니다.
명품 C++ Programming의 예제문제와 실습문제가 정말 좋으므로, 깊게 공부하고 싶다면 책을 구매하는 것을 추천드립니다.
책의 저작권 등등 각종 권한은 출판사와 지은이/옮긴이에 있습니다.
- 출판사: (주)생능 출판사
- 지음: 황기태
C++ 함수의 인자 전달 방식
C와 C++에서의 인자 전달 방식(argument passing)은 두 가지가 있다.
- 값에 의한 호출 (call by value)
- 주소에 의한 호출 (call by address)
값에 의한 호출은 함수의 매개변수에 변수의 값을 복사해서 넘겨주는 것을 말한다. 주소에 의한 호출은 함수의 매개변수에 변수의 주소를 복사해서 넘겨주는 것을 말한다. 다음의 예시를 통해 차이점을 확인해보자.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void callByValue(int a, int b) {
a++;
b++;
cout << a << " " << b << endl;
}
int main() {
int a = 1;
int b = 2;
callByValue(a, b);
cout << a << " " << b << endl;
}값에 의한 호출의 사례이다. a와 b를 함수로 보내 함수에서는 a와 b를 1씩 더하고 출력한다. 메인 함수에서 a와 b를 출력했을때 a와 b가 변화가 없이 1과 2를 출력할 것이다.

결국 값에 의한 호출은 매개변수에 값을 복사해서 새로운 변수를 만들어내는 것이라 생각하면된다.
반대로 주소에 의한 호출의 경우에는
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void callByAddress(int* a, int* b) {
*a = *a + 1;
*b = *b + 1;
cout << *a << " " << *b << endl;
}
int main() {
int a = 1;
int b = 2;
callByAddress(&a, &b);
cout << a << " " << b << endl;
}매개변수로 a와 b의 주소값을 보낸다. 주소값에 해당하는 변수값에 1을 더하고 그걸 출력하고 메인문에서 다시 출력했을 때

둘은 같은 값을 가리킨다. 이것이 주소에의한 호출이다.
여기서 코드를 짤때 굉장히 해깔리는 경우가 있다. 코드의 어떤 부분에는 * 들어가고 어떤 부분에는 들어가지 않아서 상당히 해깔게 된다. 이를 주의해야함
두 방식은 서로 장단점이 있으며, 값에 의한 호출은 실인자를 손상시키지 않게되고, 주소에 의한 호출은 함수에서 실인자의 값을 변경하고자 할 때 사용된다.
값에 의한 호출의 문제점
다음의 코드를 보도록 하자.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class food {
public:
string name = "사과";
food() {
cout << "먹이가 만들어졌습니다." << endl;
}
~food() {
cout << "먹이를 다 먹었습니다" << endl;
}
};
void eat_food(food f) {
cout << f.name << " 을 먹었습니다." << endl;
}
int main() {
food apple;
eat_food(apple);
}결과는 이런식으로 나오게 됩니다.

소멸된 객체는 2개인데, 생성된 객체는 1개입니다. 이는 컴파일러가 매개변수의 경우에 생성자를 실행하지 않고, 소멸자만 실행하도록 컴파일 하기 때문입니다. 이처럼 매개 변수 생성자가 실행되지 않고, 소멸자만 실행되는 비대칭 구조는 함수 호출 시 원본 객체의 상태를 그대로 매개변수객체에 전달되도록 하기 위한 것이지만 중대한 문제를 동반합니다. 이를 해결하기 위한 방법으로 복사생성자(copy constructor)라는 개념이 등장합니다
객체 치환 및 객체 리턴
동일한 클래스 타입에서 객체를 치환한다는 것은 객체를 같게하는 것과 같은 느낌입니다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class food {
public:
string name;
food(string name = "사과") {
this->name = name;
cout << "먹이가 만들어졌습니다." << endl;
}
~food() {
cout << "먹이를 다 먹었습니다" << endl;
}
string get_name() {
return this->name;
}
};
int main() {
food apple;
food banana("banana");
apple = banana;
}또한 get_name()함수에서 객체의 name 변수의 복사본을 리턴하는 과정을 리턴이라 합니다.
참조(reference)와 함수
C++에서 새롭게 도입되는 개념입니다. & 기호를 이용해서 이미 선언된 변수에 별명을 붙이는 작업입니다.(alias) 그래서 C++에서 참조는 다음과 같이 활용될 수 있습니다.
- 참조 변수
- 참조에 의한 호출
- 함수의 참조 리턴
참조변수
이미 선언된 변수에 대한 별명으로 참조자를 이용하여 선언(&) 하며, 선언 시 반드시 원본 변수로 초기화해야합니다.
다음처럼 참조변수의 선언을 한 번 확인해보면
int main() {
food banana("banana");
food& apple = banana;
}apple이라는 객체와 banana는 어떠한 상태인가? 하니

바나나와 사과는 동일한 메모리 공간을 공유하게 됩니다. 다시 변수를 int형으로 선언해서 계산이 어떻게 진행되는지 확인을 해봅시다.
int main() {
int n = 2;
int& refe = n;
refe = 3;
cout << refe << endl;
cout << n << endl;
n = 5;
cout << refe << endl;
cout << n << endl;
}둘은 같은 공간을 공유하고 있기 때문에 둘 중 하나의 값을 변경해도 같은 값이 나오게됩니다.

역시 이것만 하면 너무 쉽지 이상한 놈이 하나 등장하는데, 바로 참조변수와 포인터를 섞는 것인데
int main() {
int n = 2;
int& refe = n;
int* p = refe;
(해당 코드는 틀렸다)이렇게 하면 안되고
int main() {
int n = 2;
int& refe = n;
int* p = &refe;이런식으로 선언을 해주어야한다.
int main() {
int n = 2;
int& refe = n;
int* p = &refe;
refe = 3;
cout << refe << endl;
cout << n << endl;
cout << *p << endl;
n = 5;
cout << refe << endl;
cout << n << endl;
cout << *p << endl;
}그래서 3값 모두 동일한 값을 나타내게 된다.

이중포인터 처럼 이것도 이중 참조가 가능하다.
int main() {
int n = 2;
int& refe = n;
int& second_refe = refe;
참조에 의한 호출, call by reference
매개변수를 참조 타입으로 선언해서 매개 변수가 함수를 호출하는 쪽의 실인자를 참조하여 실인자의 공간을 공유하도록 하는 인자 전달 방식이다. 코드를 통해서 이해를 해보도록하자.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void callByReference(int& a, int& b) {
a = a + 1;
b = b + 1;
cout << a << " " << b << endl;
}
int main() {
int a = 1;
int b = 2;
callByReference(a, b);
cout << a << " " << b << endl;
}다음처럼 참조에 의해서 호출을 하고 실행하는 모습을 보인다. 함수로는 a와 b의 참조값이 전달되며 둘은 같은 메모리 공간을 공유한다. 그래서 결과는 다음과 같이 나오게 된다.

참조에의한 호출이 생긴 이유는 다음과 같다. 주소에 대한 호출을 반복적으로 사용하는 경우 포인터가 남발되는데, 이때 코드를 작성하는데 어려움이 생기게 된다. 이를 방지하기 위해 등장한 개념이 참조이다. 그러나 다음의 경우를 조심해야한다.
- 참조 매개 변수로 이루어진 모든 연산은 원본 객체에 대한 연산이 된다.
- 참조 매개 변수는 이름만 생성되므로, 생성자와 소멸자는 아예 실행되지 않는다.
참조 리턴
참조를 리턴하는 다음의 사례를 보도록하자.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
char c = 'a';
char& find() {
return c;
}
int main() {
char a = find();
cout << c << endl;
char& ref = find();
cout << c << endl;
ref = 'M';
cout << c << endl;
find() = 'b';
cout << c << endl;
}봐도 뭐가될지 예상이 안된다. 시작부터 a 는 'a'가 된다는 건 예상이 된다. 그 다음에 참조변수가 find와 같다 하면 a가 된다. 다시 ref는 M이 되고, 그러니 c는 M이 되고 그 다음 c는 b가 된다.

복사 생성자
복사에는 얕은복사(shallow copy)와 깊은 복사(deep copy)로 구분할 수 있다. 얕은 복사는 객체의 포인터만 복사해서 메모리를 공유한다.
깊은 복사의 경우에는 포인터의 메모리도 복사를 시킨다. 메모리도 다르게 소유한다. 그래서 얕은 복사를 진행하여 A와 B가생겼고, 내용물이 A라고 할때, B가 A를 B로 변경하면 A의 내용물도 B로 변경되는 경우가 생긴다. 개발자라면 가능한 깊은 복사를 해야한다.
복사생성자를 선언해보자.
class food {
public:
string name;
food(string name = "사과") {
this->name = name;
cout << "먹이가 만들어졌습니다." << endl;
}
// 복사생성자
food(const food& f) {
this->name = name;
}
~food() {
cout << "먹이를 다 먹었습니다" << endl;
}
string get_name() {
return this->name;
}
};다음에서 표시된 부분이 복사생성자이다. 한 번 복사를 하는 예시를 보자.
int main() {
food banana("banana");
food apple(banana);
}다음의 과정을 통해 복사가 진행된다. 또한 추가적으로 복사생성자가 없어도 컴파일러는 알아서 복사생성자를 하나 생성한다. 여튼 컴파일러가 직접 삽인한 복사생성자건, 개발자가 만든 복사생성자건 얕은 복사가 발생할 우려가 있다.
다음의 코드를 한 번 살펴보자.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <string>
using namespace std;
class animal
{
public:
char* name;
int age;
animal(const char* name, int age)
{
this->name = new char[strlen(name) + 1];
strcpy(this->name, name);
this->age = age;
}
void set_name(const char* name) {
strcpy(this->name, name);
}
};
int main(void)
{
animal dog = animal("dog", 5);
animal cat(dog);
cout << dog.name << " " << dog.age << endl;
cout << cat.name << " " << cat.age << endl;
cat.set_name("cat");
cout << dog.name << " " << dog.age << endl;
cout << cat.name << " " << cat.age << endl;
getchar();
}이 경우에 결과는 어떻게 나오는지 확인을 해보자.
우선 dog 객체를복사해서 cat의 이름을 cat으로 변경한경우이다.

그러나 dog의 경우에도 이름이 dog로 바뀐 것을 확인할 수 있다.
결과만 보면 잘 복사가 되었다고 이해할 수 있으나 한 번 뜯어보아야한다. 왜 이런일이 발생하는지 뜯어보면

얕은 복사가 일어나서 같은 주소를 공유하기 때문이다. 문제는 이뿐만이 아니다.
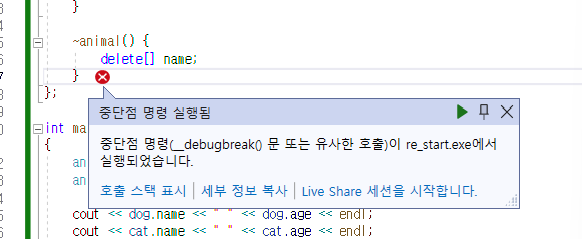
다음과 같은 오류가 발생한다. 이는 이미 반환된 객체를 다시 반환하려고 하니 일어나는 문제이다. 왜 이런 일이 발생하는가? cat객체가 먼저 소멸된 후 name에 할당된 메모리를 반환하는데, dog의 name이 반환을 하러갈때 컴파일러가 "너 아까 반환했는데, 왜 또 반환해?" 하면서 오류가 발생하는 것이다.

이를 방지하기 위해서는 깊은 복사를 해야한다. 다음과 같은 코드를 따라야한다. 깊은 복사 생성자를 하나 작성하자.
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <string>
using namespace std;
class animal
{
public:
char* name;
int age;
animal(const char* name, int age)
{
this->name = new char[strlen(name) + 1];
strcpy(this->name, name);
this->age = age;
}
animal(const animal& animal) {
this->age = animal.age;
this->name = new char[strlen(animal.name) + 1];
strcpy(this->name, animal.name);
}
void set_name(const char* name) {
strcpy(this->name, name);
}
~animal() {
delete[] name;
}
};
int main(void)
{
animal dog = animal("dog", 5);
animal cat(dog);
cout << dog.name << " " << dog.age << endl;
cout << cat.name << " " << cat.age << endl;
cat.set_name("cat");
cout << dog.name << " " << dog.age << endl;
cout << cat.name << " " << cat.age << endl;
}깊은 복사의 특징은 객체자체를 받아오는 것이다.


서로 다른 주소값을 가지게 됨으로 깊은 복사가 실현되었다. 문제없이 종료도 가능해진다.
책의 저자는 묵시적인 복사생성을 주의하라고 한다. 묵시적인 복사 생성이란, 나도 모르는 사이에 복사생성자가 실행되어, 얉은 복사가 일어나는 것을 말한다. 그 때는 다음과 같다.
1. 객체로 초기화하여 객체가 생성될때
2. 값에 의한 호출로 객체가 전달될 때
3. 함수가 객체를 리턴할 때
참고 문헌
Scott Douglas Meyers(2015). Effective C++. Protec Media(프로텍 미디어)
Robert C. Martin(2021).UML 실전에서는 이것만 쓴다(UML for Java Programmers). 인사이트
황기태(2021). 명품 C++ Programming. (주)생능출판사
'ㅇ 공부#언어 > (C++)기초' 카테고리의 다른 글
| (기초 C++) 7장. C++에서의 프랜드와 연산자 중복 (0) | 2023.03.01 |
|---|---|
| (기초 C++) 6장. C++에서의 함수 중복과 static 멤버 (0) | 2023.02.26 |
| (기초 C++) 4장. C++에서의 포인터 및 동적 생성 (string 클래스 활용) (0) | 2023.02.26 |
| (기초 C++) 3장. C++에서 클래스 사용법 (0) | 2023.02.25 |
| (기초 C++) 2장. C와는 다른 C++의 기초 문법 (0) | 2023.02.25 |