
데이터 출처
2019~2022년 서울시 도로별 통행속도 데이터
속도 정보 | 서울시 교통정보 시스템 - TOPIS (seoul.go.kr)
속도 정보 | 서울시 교통정보 시스템 - TOPIS
속도정보 안내 서울시 차량통행속도 생성개요 수집기간 : 1년 365일, 24시간 (00~24시) 수집범위 : 서울특별시 505개 도로 총 연장 : 1,471.1km 생성방법 : 수집 ⇒ 가공 ⇒ 제공 - 도시고속도로 : 영상검
topis.seoul.go.kr
구글 API 및 카카오지도
우선 서울시 도로별 통행속도 데이터를 가져와봅시다.
(데이터가 너무 많기 때문에 2019~2022년 10월의 데이터만 가공을 합니다.)
speed = pd.read_excel('./서울시 도로별 통행속도.xlsx')
speed저는 파일이름을 바꿔놓았습니다.
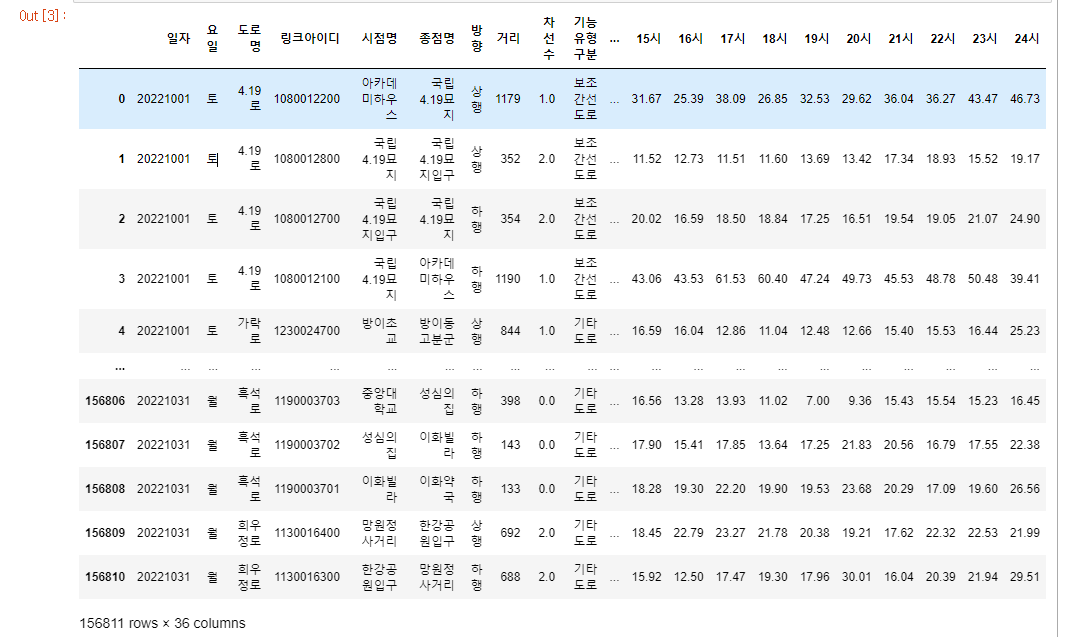
우선은 이 데이터에서 도로별 위치정보를 뽑아내려고 합니다.
2021년부로 서울시 도로별 위치정보 데이터가 비공개처리가 되었습니다.
시간관계상 따로 신청을 하고 사용승인을 받을 여유가 없어서 직접 위도 경도를 뽑으려고 합니다.
현재 데이터는 2022년 10월 01일부터 2022년 10월 31일 까지의 데이터가 있으니
여기서 2022년 10월 01일의 데이터만 뽑아냅시다.
speed_2022_10_01 = speed[speed['일자'].isin([20221001])]
speed_2022_10_01

위치를 검색하기 위해서 필요한 것이 무엇일까? 결국 도로명과 시점명 종점명일 것입니다.
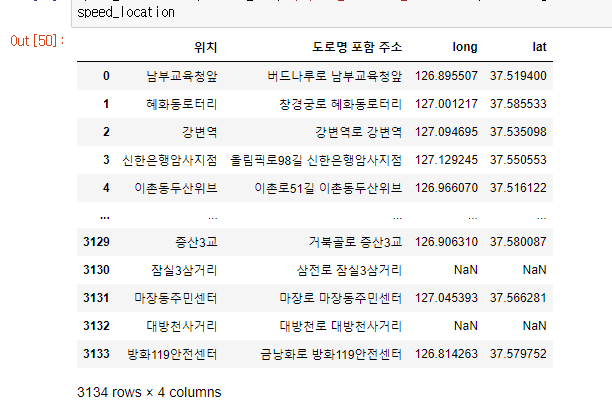
speed_location = speed_2022_10_01[["도로명", "시점명", "종점명"]]
speed_location
코드상에서는 두가지 상황으로 나누었습니다.
1. 시점명이나 종점명을 검색해서 위도경도를 얻기
2. 도로명 + 시점명, 종점명으로 검색해서 위도,경도를 얻기
그러나 이후에 생각해낸 것으로는
"서울" + 시점명 으로 만들어 주는 것도 좋을 것이라 생각합니다.
생각보다 놓치거나 이상한 곳으로 검색하는 경우가 많아서, 서울로 한정시켜버리는 것입니다.
speed_location["시점 주소"] = speed_location["도로명"] +" " + speed_location["시점명"]
speed_location["종점 주소"] = speed_location["도로명"] +" " + speed_location["종점명"]
speed_location
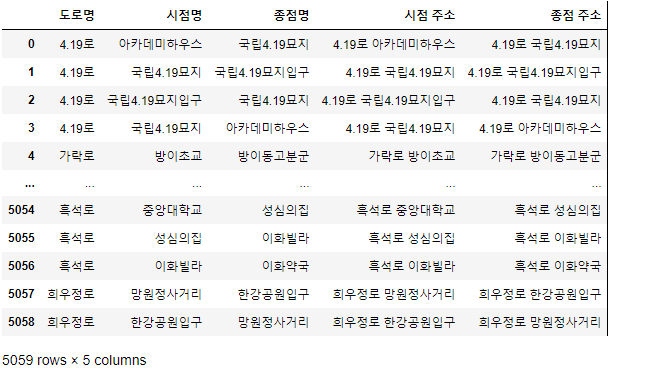
시점주소에서도 중복데이터가 있고, 종점 주소에서도 중복데이터가 있습니다.
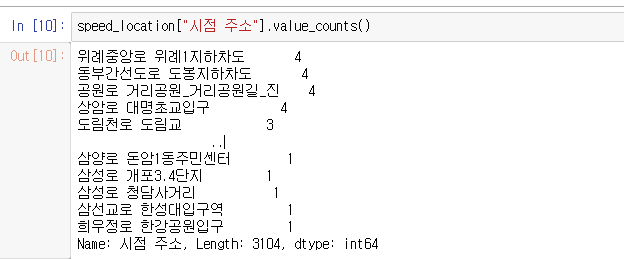
그러니까 시점주소, 종점주소값을 리스트형식으로 변환하고, 합치고, 중복값을 제거합니다.
speed_location_list = speed_location["시점 주소"].to_list()
speed_location_list_2 = speed_location["종점 주소"].to_list()
speed_location_list_sum = speed_location_list + speed_location_list_2
len(speed_location_list_sum)
speed_location_list_final = list(set(speed_location_list_sum))
len(speed_location_list_final)
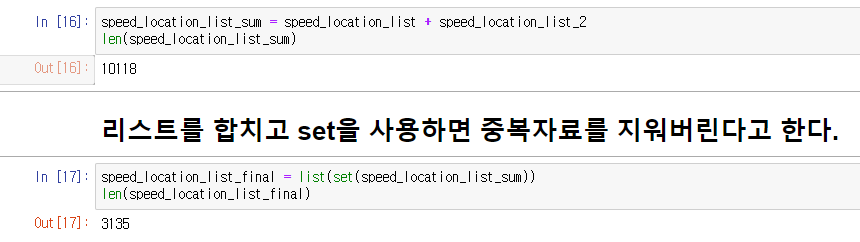
3135개로 데이터가 줄었다.
nan이 존재하니 이걸 없애자.
그리고 데이터프레임으로 만들자.
import numpy as np
speed_location_pd = pd.DataFrame(speed_location_list_final)
speed_location_pd = speed_location_pd.dropna()
speed_location_pd
nan을 지울경우 인덱스가 이상해진다. 그러니 reset_index()을 해주어야 한다.
speed_location_pd =speed_location_pd.reset_index()
speed_location_pd = speed_location_pd.drop(['index'], axis=1 )
speed_location_pd

왜인지 모르겠는데, 컬럼이 4개가 아니라고 연산을 안해줬다.
df2 = pd.DataFrame(speed_location_pd[0].str.split(' ').tolist(),columns=['도로', '위치', '야', '호'])
df2
원본에서 주소랑 위치를 비교해서
위치 + 도로명 주소를 포함하는 주소 두 가지 컬럼을 가지는 데이터프레임을 얻는다.
speed_location_pd["위치"] = df2["위치"]
speed_location_pd['도로명 포함 주소'] = speed_location_pd[0]
speed_location_pd = speed_location_pd.drop([0], axis=1)
speed_location_pd
그런데, 여기서 한가지 더 추가하자면
speed_location_pd["서울포함 주소"] = "서울" + speed_location_pd["위치"]이걸 하나 추가해서 위치대신에 서울포함 주소를 검색하게 하는 것이 좋다고 생각한다.
결국 이제 써야하는 것은
구글 API
pip install googlemaps뭐 여기서 깔아 쓸 수도 있겠지만,
보통은 Anaconda Prompt나 터미널에서 가상환경을 선택하고 다운을 받는게 좋다.
from googlemaps import Client as GoogleMaps구글API에서 구글맵을 사용할 것이기 때문에 대충 import 해주고
구글API는 인터넷에 검색하고 가입을 쉽게할 수 있다.
근데, 기한이 정해져 있거나 리미트가 걸려있기 때문에 주의해야함.
gmaps = GoogleMaps('API 주소')API 주소를 통해서 잘 연결되었나 테스트를 하나 할 것이다.
speed_location_pd['long'] = ""
speed_location_pd['lat'] = ""위도 컬럼, 경도 컬럼을 추가하자.
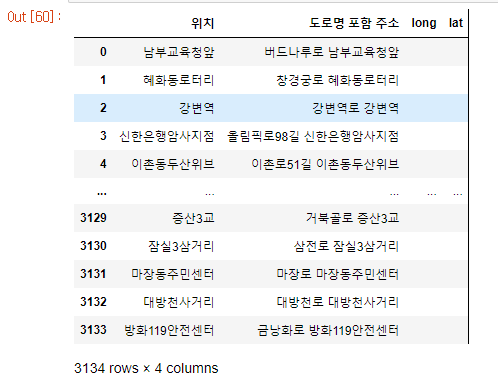
3134개나 되는 양의 데이터를 구글API를 통해 검색하기 때문에
시간이 오래걸린다. 그러므로 진행상태를 알고 싶다면 tqdm을 사용하면 된다.
pip install tqdm
import time
from tqdm import tqdm
fail_list = []
fail_location_list = []
for x in tqdm(range(len(speed_location_pd))):
try:
time.sleep(1.0) #to add delay in case of large DFs
geocode_result = gmaps.geocode(speed_location_pd["위치"][x])
speed_location_pd['lat'][x] = geocode_result[0]['geometry']['location'] ['lat']
speed_location_pd['long'][x] = geocode_result[0]['geometry']['location']['lng']
except IndexError:
try:
time.sleep(1) #to add delay in case of large DFs
geocode_result = gmaps.geocode(speed_location_pd['도로명 포함 주소'][x])
speed_location_pd['lat'][x] = geocode_result[0]['geometry']['location'] ['lat']
speed_location_pd['long'][x] = geocode_result[0]['geometry']['location']['lng']
except:
fail_list.append(x)
fail_location_list.append(speed_location_pd["도로명 포함 주소"][x])
except Exception as e:
print(x, "- Unexpected error occurred.", e )
speed_location_pd
코드는 이렇다. 일단 위치 컬럼으로 한 번 검색해서 결과나오면 위도경도 저장해줘
근데 실패하면 도로명주소를 포함해서 한 번 더 검색해줘
거기서도 실패하면 인덱스랑 위치정보를 저장해줘.
(근데, 만약 혹시 이를 따라해볼 분이 있다면 위치컬럼으로 검색하기 전에 "서울" 을 추가해서 검색하자.)
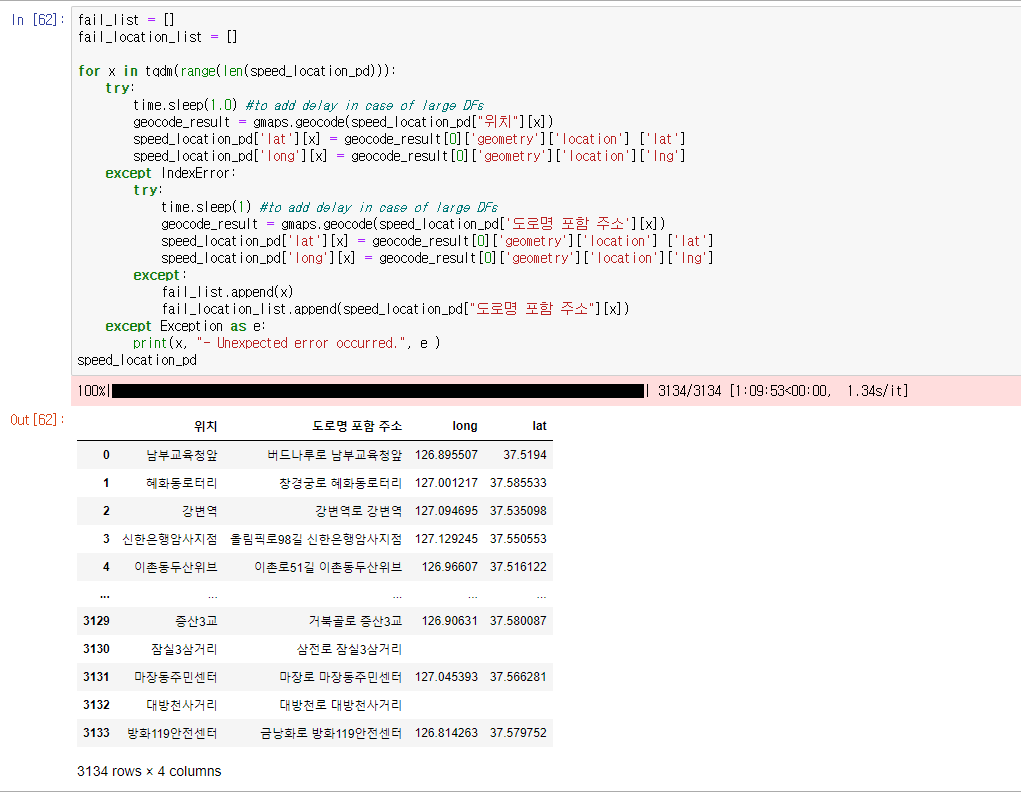
다른 사람은 어떨지 모르겠지만, 보이는 것처럼 1시간 10분정도 걸린다.
문제는 여기서 실패하는 경우
일단 미리 대비를 해놓았다.

실패한 인덱스와 위치정보를 저장해두었기 때문

이를 하나의 데이터프레임으로 만들어버리자.
이걸 구글 API로 해결할 수 없다면... 다른 방법을 사용해야한다.
이번에는 웹크롤링으로 나머지 위도경도를 뽑아내자.
지도의 위치에도 주소가 바뀌지 않는 동적? 정적? 뭐시기 사이트라
동적사이트라서..
셀레니움을 사용해야합니다.
구글API로 만들었던 데이터프레임을 가져옵니다.
speed_location = speed_location.fillna(0)이걸로 NaN을 모두 0으로 바꿔주시구요
여튼 그전에
구글API를 믿을 수 있을까?
확인을 해주는 작업이 필요합니다.
구글지도를 일단켜고 서울시 경계면의 위도 경도를 찍어봅니다.
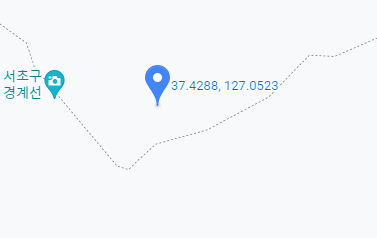
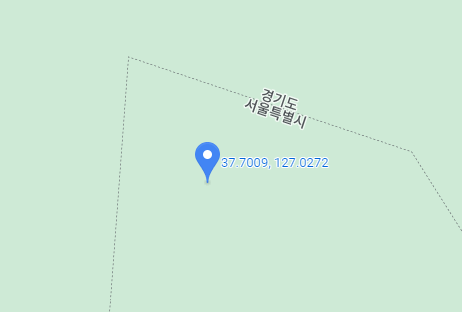
위도범위는 조금 보수적으로 37.2 ~37.6 이내의 범위를 가지게
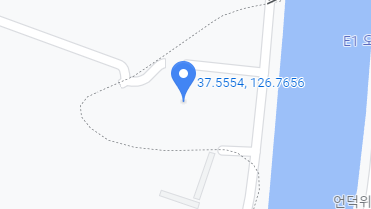

경도범위는 조금 보수적으로 126.5 ~127.5 이내의 범위를 가지는 값만 살리고 그 외는 지웁니다.
a = speed_location[speed_location['long'] <= 126.5]
b = speed_location[speed_location['lat'] <= 37.2]
c = speed_location[speed_location['long'] >= 127.5]
d = speed_location[speed_location['lat'] >= 37.6]
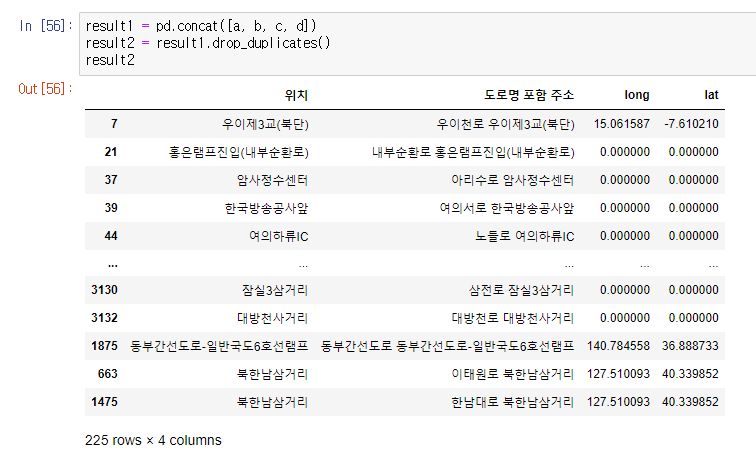
result1 = pd.concat([a, b, c, d])
result2 = result1.drop_duplicates()
result2
result_reset_inext =result2.reset_index()
result_reset_inext = result_reset_inext.drop(['long', 'lat'], axis=1)
result_reset_inext['url'] = ""
result_reset_inext['long'] = ""
result_reset_inext['lat'] = ""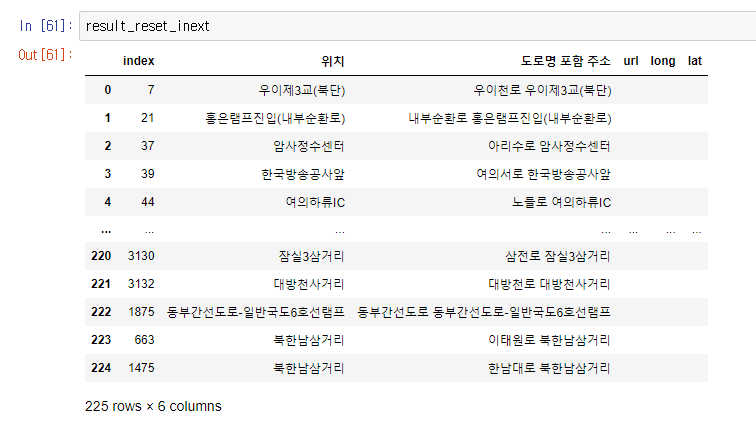
위도, 경도를 삭제하고 다시 만들어줬다.
url을 만든이유는 카카오지도에서 설명하겠다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
from bs4 import BeautifulSoup
import time
from tqdm import tqdm여튼 셀레니움을 사용하기 위해서는
크롬 드라이버를 다운받아야하니 그걸 다운받아서 잘 넣어주도록하자.
ChromeDriver - WebDriver for Chrome - Downloads (chromium.org)
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 108, please download ChromeDriver 108.0.5359.22 If you are using Chrome version 107, please download ChromeDriver 107.0.5304.62 If you are using Chrome version 106, please download ChromeDriver 106.0.5249.61
chromedriver.chromium.org
일단 위치정보를 리스트로 저장하자.
result_index_list = result_reset_inext['index'].to_list()
result_address_list = result_reset_inext['위치'].to_list()
result_address_list_setting = []
for i in range(len(result_address_list)):
result_address_list_split = result_address_list[i].split('(')
result_address_list_setting.append(result_address_list_split[0])
result_address_list_setting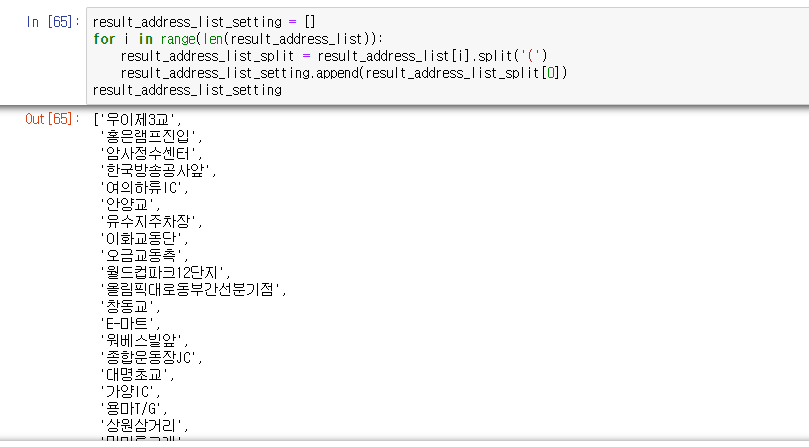
여기도 서울을 붙여주자
for i in range(len(result_address_list_setting)):
result_address_list_setting[i] = result_address_list_setting[i].replace("진입", "")
result_address_list_setting[i] = "서울 " + result_address_list_setting[i]
result_address_list_setting

chrome_options = webdriver.ChromeOptions()
url = "https://map.kakao.com/"
driver = webdriver.Chrome(service=Service("./driver/chromedriver.exe"), options=chrome_options)
driver.get(url)이 코드를 실행하면 크롬이 카카오지도를 켠다.
카카오지도를 셀레니움으로 크롤링 할 때 조심해야한다.
크롬드라이버로 작동시키면 이게 뜬다. 그러니 자동이라고 좋다고 딴짓하지 말고
카카오지도카 켜지면 지도를 한 번 클릭해줘야한다.
그리고 셀레니움이 진행되는 동안에도 20~100번 중 한 번 정도 저게 나온다.
저걸 꺼줘야만 정상적으로 진행된다.
우리가 카카오지도에서 뽑아야하는 정보는 URL 이다.
fail_index = []
adress = []
road_adress = []
for i in tqdm(range(len(result_address_list_setting))):
css_selector = '''#search\.keyword\.query'''
search_docs = driver.find_element(By.CSS_SELECTOR, css_selector).send_keys(result_address_list_setting[i] + Keys.ENTER)
time.sleep(0.5)
try:
searh_result = driver.find_element(By.CLASS_NAME, "tit_name").click()
time.sleep(0.5)
searh_result = driver.find_element(By.CLASS_NAME, "tit_tool").click()
time.sleep(0.5)
searh_result = driver.find_element(By.ID, "tool.map.copyurl").click()
time.sleep(0.5)
result_reset_inext_2['url'][i] = driver.find_element(By.CLASS_NAME, "txt_url").text
xpath_search_result = '''//*[@id="shareUrl"]/div/div[1]/button/span'''
search_btn = driver.find_element(By.XPATH, xpath_search_result).click()
time.sleep(0.5)
except:
print('카카오로도 해결할 수 없다.')
fail_index.append(i)
adress.append(result_reset_inext['위치'][i])
road_adress.append(result_reset_inext['도로명 포함 주소'][i])
search_docs = driver.find_element(By.CSS_SELECTOR, css_selector).clear()
time.sleep(0.5)
# 메크로 방지를 위해서 손이 한 번 들어가야함.
if i == 20:
print("지도를 터치하세요.")
time.sleep(10)
result_reset_inext_2여튼 이건 개발자모드를 통해 HTML 코드를 분석하고 만든 코드이다.
크롤링 시간이 아니라 내가 데이터를 어떻게 뽑았냐 이걸 설명하는 글이 되고 싶어서 어떻게 했는지는 생략을 할까싶다.
근데 개발자모드만 쓰고 할줄만알면 정말 어렵지 않고 쉽다. (다른 프로젝트에 상세하게 적혀있으니)
여튼 이 코드르 실행하면 직접 검색을 하면서 url을 저장한다.
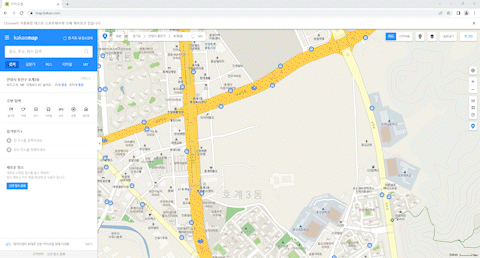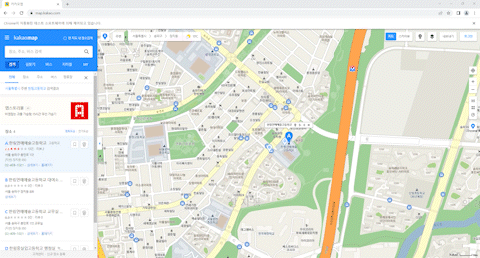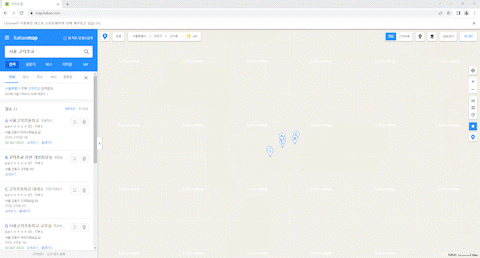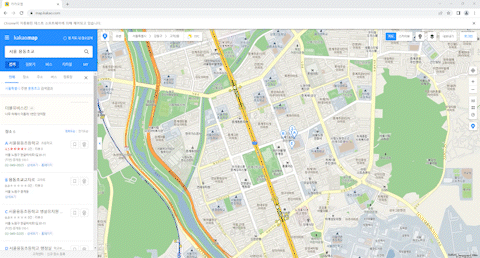
이 url을 저장하고

약 10분정도 기다려주면 (지켜봐주면) url을 저장해준다.
result_reset_inext_3 = result_reset_inext_2
result_reset_inext_3 = result_reset_inext_3.drop(['index', '실패인덱스', '실패_인덱스'], axis=1)
result_reset_inext_3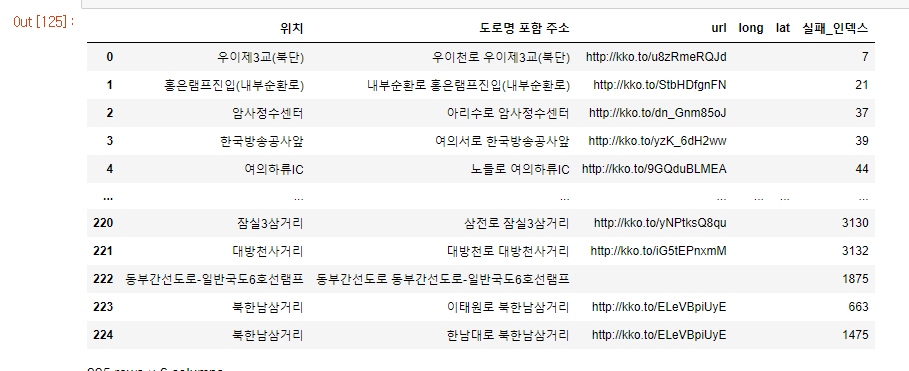
실패한 것만 인덱스로 만들어놓고
fail_list_kakao = pd.DataFrame({'실패인덱스':fail_index})
fail_list_kakao
합치고
merge_left = pd.merge(fail_list_kakao,result_reset_inext_3, how='right', left_on='실패인덱스', right_on='index')
df = merge_left.dropna()
dfnan을 모두 지워버리면
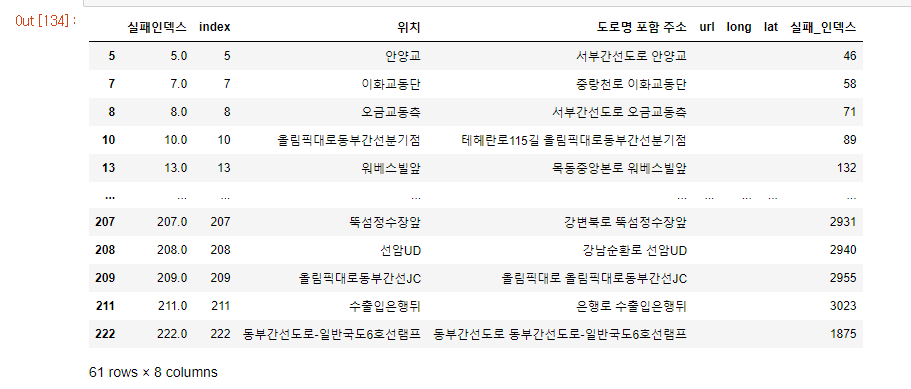
실패한 애들만 남는다.
어.. 이건 도저히 방법이 없어 수작업으로 모두 추가해주었다.
자동화할 방법이 없다.
그러면 그 URL을 어떻게 할거냐.
지도 위도 경도
지도 위도 경도
xn--yq5bk9r.com

해당 사이트에 url을 적어놓으면 위도 경도를 알려준다. 그 값을 긁어오면 된다.
chrome_options = webdriver.ChromeOptions()
url = "https://xn--yq5bk9r.com/blog/map-coordinates"
driver = webdriver.Chrome(service=Service("./driver/chromedriver.exe"), options=chrome_options)
driver.get(url)
css_selector = '''#__next > div > div > main > div.mx-auto.max-w-3xl.px-4.sm\:px-6.xl\:max-w-5xl.xl\:px-0 > article > div > div > div > div.prose.max-w-none.pt-10.pb-8.dark\:prose-dark > div > div.flex.flex-col.space-y-4 > div.flex.flex-col.space-y-4 > input'''
search_docs = driver.find_element(By.CSS_SELECTOR, css_selector).send_keys(url_list[0])
time.sleep(1.0)
xpath ='//*[@id="__next"]/div/div/main/div[3]/article/div/div/div/div[1]/div/div[2]/div[1]/button'
search_btn = driver.find_element(By.XPATH, xpath).click()
time.sleep(3.0)
Xpath = '//*[@id="__next"]/div/div/main/div[3]/article/div/div/div/div[1]/div/div[2]/div[2]/div/div[1]/text()[2]'
text = driver.find_element(By.XPATH, xpath)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
gage = soup.find_all(class_ = "flex flex-col space-y-4")
gage_text = gage[0].text
gage_split = gage_text.split(" ")
search_docs = driver.find_element(By.CSS_SELECTOR, css_selector).clear()
time.sleep(0.5)
이 코드를 넣어주면 밑처럼 동작한다.
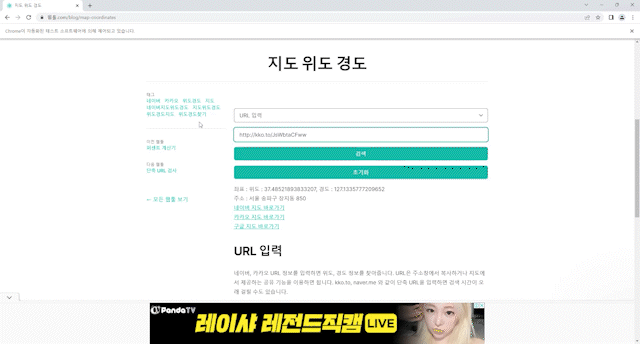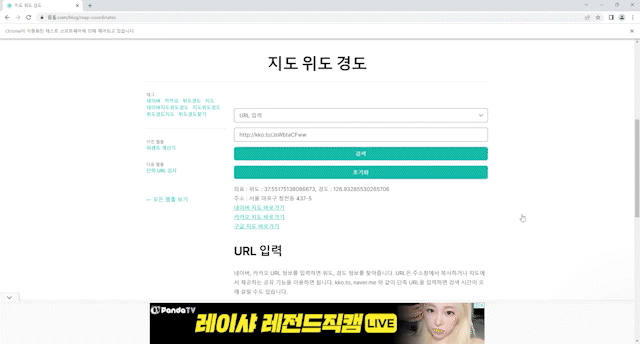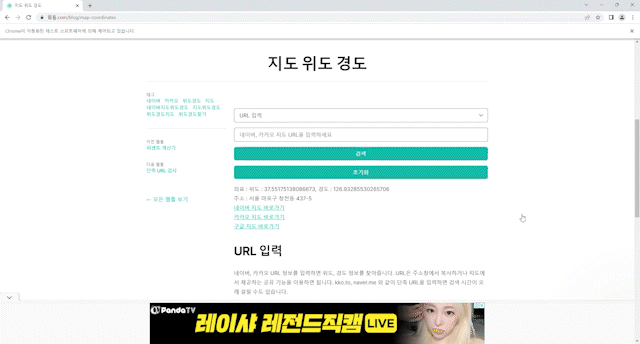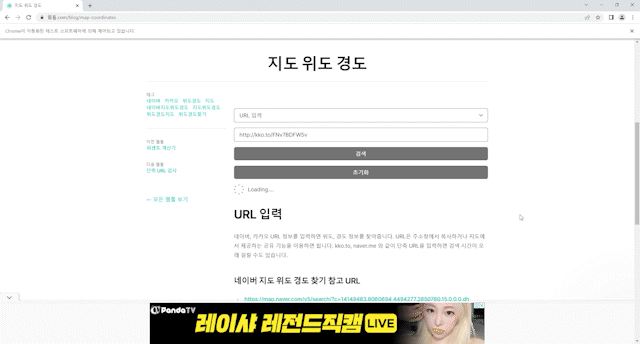
후.. 여튼 이렇게 하면
서울시 도로별 위도경도 데이터를 얻을 수 있다.
(뭐 구글API로 구했던 것과 merge하는걸 빼먹었지만 쉽게 할 수 있을것이다.)
그러나 앞서 보았지만, 정확도는 보장하지 못한다.
서울시에서 제공하는 정보가 아니며, 모두 크롤링을 통해 긁어모은 정보이기 때문이다.

이제 한 번 지도에 찍어보자고
import pandas as pd
import folium
location = pd.read_csv('./2022_10_자동차_평균속도_위치데이터.csv', encoding='EUC-KR')
location
문제는 뭐냐면 5km가 넘는 선이 그려진다는 것이다.
어쩔 수 없는 크롤링의 한계라고 생각한다.
location.sort_values(by='거리' ,ascending=False)
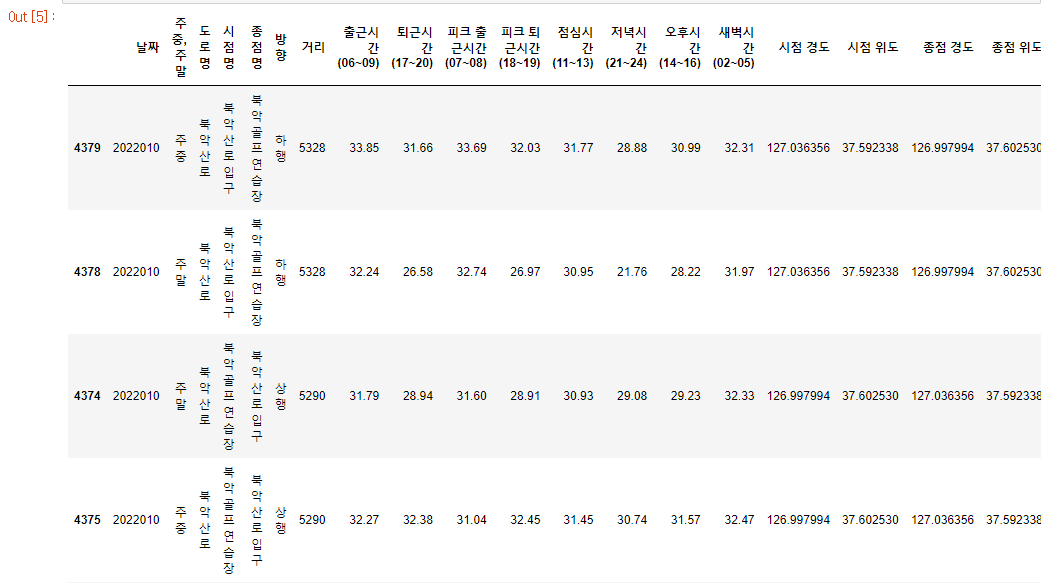
그러니 5km를 넘어서는 시점종점값은 걍 그리지 말자.
그림은 한 번 퇴근시간으로 그려보자고
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
for each in range(len(location)):
start = (location['시점 위도'][each], location['시점 경도'][each])
end = (location['종점 위도'][each], location['종점 경도'][each])
a = haversine(start, end, unit = 'km')
if a < 5.5:
if location['방향'][each] == "상행":
location_data = [[location['시점 위도'][each], location['시점 경도'][each]],
[location['종점 위도'][each], location['종점 경도'][each]]]
if location['방향'][each] == "하행":
location_data = [[float(location['시점 위도'][each])+0.0001, float(location['시점 경도'][each]+0.0006)],
[float(location['종점 위도'][each])+0.0001, float(location['종점 경도'][each])+0.0006]]
if location['피크 퇴근시간 (18~19)'][each] >= 25:
folium.PolyLine(locations=location_data, tooltip='Polyline', color='green').add_to(my_map)
elif location['피크 퇴근시간 (18~19)'][each] > 15:
folium.PolyLine(locations=location_data, tooltip='Polyline', color="yellow").add_to(my_map)
else:
folium.PolyLine(locations=location_data, tooltip='Polyline', color='red').add_to(my_map)
뭐 대충 시점 종점으로 그림 그리자라는 코드이다.
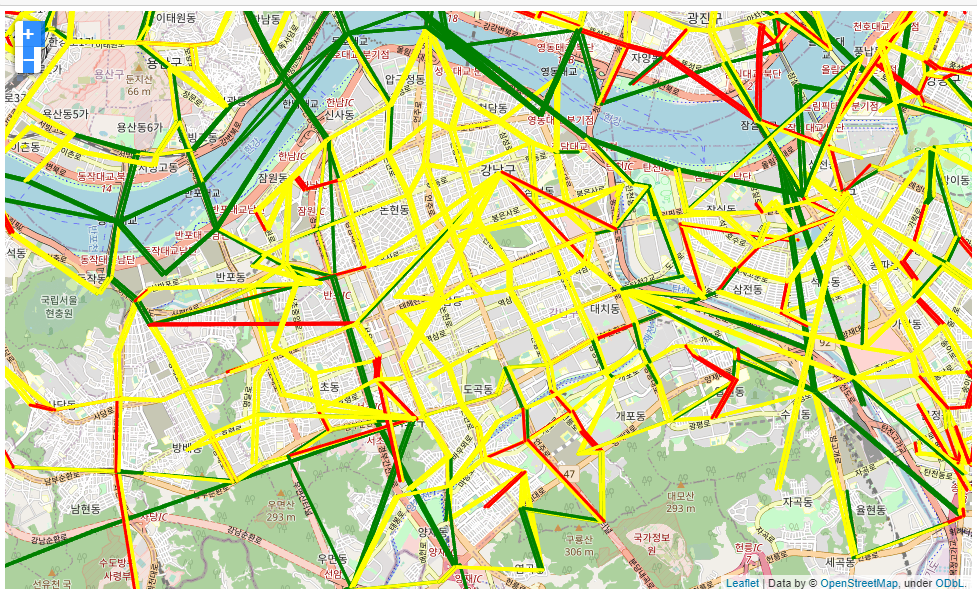
그러면 결과로 이런 그림을 그려준다.
(초록)원활 : 25km/h 이상 , (노랑)서행 15km/h 초과 , (빨강) 정체 15km/h 이하

강남을 봐볼까?
용산
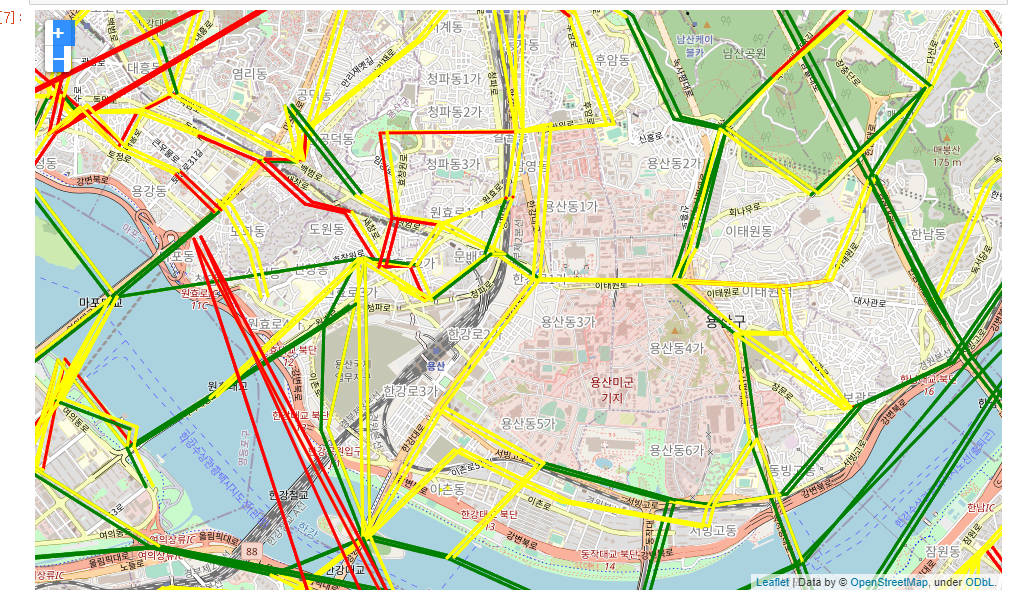
직선으로 이은 것도 있기 때문에 이해를 해주셨으면 한다.
여튼 이렇게 마무리를 하고
승용차 데이터 가공은 얼마 안남았다. 글을 한 번 더 써야할 것 같다.
'취업전 프로젝트 > TEAM_서울시 교통 인프라 분석' 카테고리의 다른 글
| 7. 서울시 상권데이터를 분석하자. (0) | 2022.11.19 |
|---|---|
| 6. 서울시 승용차 평균속도 데이터 가공 (0) | 2022.11.19 |
| 4. (EDA_프로젝트) 서울시 지하철 데이터로 지하철 노선도를 그려보자. (1) | 2022.11.14 |
| 3. (EDA_프로젝트) 서울시 지하철 데이터를 수집하고 가공하자. (1) | 2022.11.14 |
| 2. (EDA_프로젝트) 서울시 버스 데이터를 수집하고 가공하자. (0) | 2022.11.14 |