서울시 공공데이터를 활용해서
정류장별 승하차 인원 수, 정류장의 위치정보를 구해보자.

데이터 수집
서울시 버스정류소 위치정보
서울시 버스정류소 위치정보> 데이터셋> 공공데이터 | 서울열린데이터광장 (seoul.go.kr)
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
서울시 버스노선별 정류장별 시간대별 승하차 인원 정보
서울시 버스노선별 정류장별 시간대별 승하차 인원 정보> 데이터셋> 공공데이터 | 서울열린데이터광장 (seoul.go.kr)
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
데이터 전처리 진행하기
들어가기전
환경을 꼭 체크해야 합니다.
서울시 공공데이터들의 인코딩은 모두 EUC-KR 입니다.
판다스의 디폴트 인코딩은 UTF-8이기 때문에 문제가 발생합니다.
쥬피터 켜기 귀찮아서 깃헙에 올린 쥬피터 노트북 코드를 기준으로 설명합니다.
import pandas as pd
import numpy as np판다스를 import 합시다.
서울시 버스정류소 위치정보를 먼저 불러와 봅시다.
seoul_bus_stop_commute = pd.read_csv('./2022_bus_stop_원본.csv', encoding = 'EUC-KR')
seoul_bus_stop_commute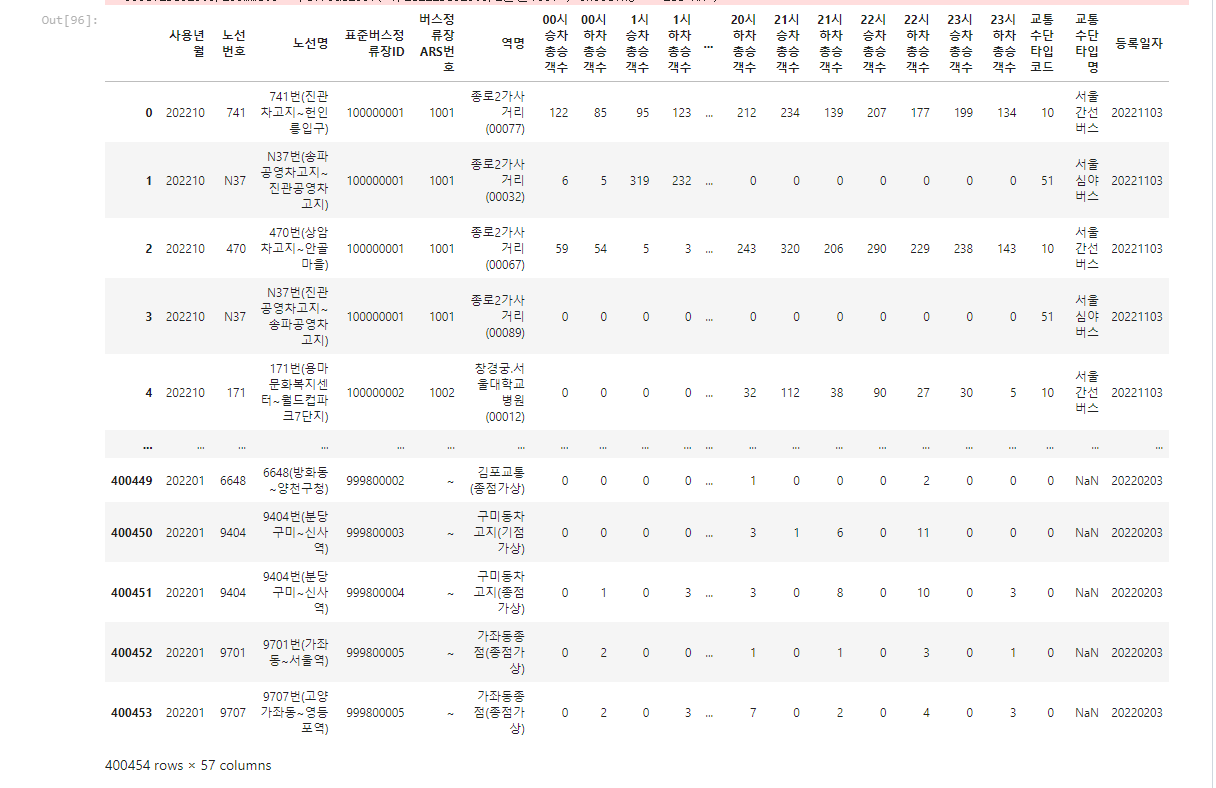
40만개의 데이터가 들어 있기 때문에 데이터를 조금 줄여야할 필요성이 있습니다.
그리고 칼럼이 너무 많기 때문에 필요없는 칼럼을 지우도록 합니다.
# 2022년 만seoul_bus_stop_commute = seoul_bus_stop_commute.drop(['버스정류장ARS번호','노선명', '교통수단타입코드', '등록일자', '교통수단타입명'], axis = 1 )
seoul_bus_stop_commute = seoul_bus_stop_commute.drop(['버스정류장ARS번호','노선명', '등록일자'], axis = 1 )
seoul_bus_stop_commute
시간별 데이터가 있으면 좋겠지만 그러면 컬럼이 너무나도 많습니다.
그러니 다음의 기준을 따라 시간대 컬럼들을 압축시켜버립시다.
출근시간
- 승차 : 4시~10시까지 (버스에서는 10시는 제외)
- 하차 : 7시~11시까지 (버스에서는 11시는 제외)
퇴근시간
- 승차 : 16시~20시까지 (버스에서는 20시는 제외)
- 하차 : 17시~21시까지 (버스에서는 21시는 제외)
늦게 퇴근하는 사람
- 승차 : 20시 ~ 01시 (버스에서는 20시 포함, 21시 제외) (지하철은 02시까지 탑승)
- 하차 : 21시 ~ 04시 (버스에서는 21시 포함, 04시 제외) (지하철은 04시까지 탑승)
점심시간
- 출근시간에 하차한 인원이 모두 점심을 먹는다 가정
- 11시 ~ 1시까지 하차한 사람 (버스에서는 1시 제외)
- 11시 ~ 1시까지 승차한 사람 (버스에서는 1시 제외)
- 출근시간하차 11부터1시하차를 더하고 11부터1시승차를 뺀다 = 점심시간유동인구
저녁시간
- 출근시간에 하차한사람에서 17시부터 20시 승차한 인원을 빼고 17시부터 20시 하차한사람을 더한값
- 이 사람이 저녁을 먹는지는 중요하지 않다고 생각함 -> 어차피 상권을 지나는 유동인구이기 때문
모든 시간의 총승차인원
모든 시간의 총하차인원
seoul_bus_stop_commute['출근시간(04~10) 승차'] = seoul_bus_stop_commute['4시승차총승객수'] + seoul_bus_stop_commute['5시승차총승객수'] + \
seoul_bus_stop_commute['6시승차총승객수'] + seoul_bus_stop_commute['7시승차총승객수'] + \
seoul_bus_stop_commute['8시승차총승객수'] + seoul_bus_stop_commute['9시승차총승객수']seoul_bus_stop_commute['출근시간(07~10) 하차'] = seoul_bus_stop_commute['7시하차총승객수'] + seoul_bus_stop_commute['8시하차총승객수'] + \
seoul_bus_stop_commute['9시하차총승객수'] + seoul_bus_stop_commute['10시하차총승객수']seoul_bus_stop_commute['퇴근시간(16~20) 승차'] = seoul_bus_stop_commute['16시승차총승객수'] + seoul_bus_stop_commute['17시승차총승객수'] + \
seoul_bus_stop_commute['18시승차총승객수'] + seoul_bus_stop_commute['19시승차총승객수']seoul_bus_stop_commute['퇴근시간(17~21) 하차'] = seoul_bus_stop_commute['17시하차총승객수'] + seoul_bus_stop_commute['18시하차총승객수'] + \
seoul_bus_stop_commute['19시하차총승객수'] + seoul_bus_stop_commute['20시하차총승객수'] + \
seoul_bus_stop_commute['21시하차총승객수']seoul_bus_stop_commute['점심시간'] = seoul_bus_stop_commute['출근시간(07~10) 하차'] - seoul_bus_stop_commute['11시승차총승객수'] -\
seoul_bus_stop_commute['12시승차총승객수'] + seoul_bus_stop_commute['11시하차총승객수'] + \
seoul_bus_stop_commute['12시하차총승객수']seoul_bus_stop_commute['저녁시간'] = seoul_bus_stop_commute['출근시간(07~10) 하차'] - seoul_bus_stop_commute['17시승차총승객수'] -\
seoul_bus_stop_commute['18시승차총승객수'] - seoul_bus_stop_commute['19시승차총승객수'] + \
seoul_bus_stop_commute['17시하차총승객수'] +\
seoul_bus_stop_commute['18시하차총승객수'] + seoul_bus_stop_commute['19시하차총승객수']seoul_bus_stop_commute['늦은시간(20~00) 승차'] = seoul_bus_stop_commute['20시승차총승객수'] + seoul_bus_stop_commute['21시승차총승객수'] + \
seoul_bus_stop_commute['22시승차총승객수'] + seoul_bus_stop_commute['23시승차총승객수'] + \
seoul_bus_stop_commute['00시승차총승객수']seoul_bus_stop_commute['늦은시간(21~02) 하차'] = seoul_bus_stop_commute['21시하차총승객수'] + seoul_bus_stop_commute['22시하차총승객수'] + \
seoul_bus_stop_commute['23시하차총승객수'] + seoul_bus_stop_commute['00시하차총승객수'] + \
seoul_bus_stop_commute['1시하차총승객수'] + seoul_bus_stop_commute['2시하차총승객수']
seoul_bus_stop_commute['총 승차 인원'] = seoul_bus_stop_commute['00시승차총승객수']
for i in range(1,24):
STR = str(i) + "시승차총승객수"
seoul_bus_stop_commute['총 승차 인원'] = seoul_bus_stop_commute['총 승차 인원'] + seoul_bus_stop_commute[STR]seoul_bus_stop_commute['총 하차 인원'] = seoul_bus_stop_commute['00시하차총승객수']
for i in range(1,24):
STR = str(i) + "시하차총승객수"
seoul_bus_stop_commute['총 하차 인원'] = seoul_bus_stop_commute['총 하차 인원'] + seoul_bus_stop_commute[STR]
그리고 0시 ~ 21시 승차와 하차 인원 컬럼을 제거하자
# 이제 각 시간별 인원은 필요가 없다
seoul_bus_stop_commute = seoul_bus_stop_commute.drop(['00시승차총승객수', '00시하차총승객수'], axis = 1 )
for i in range(1,24):
STR = str(i) + "시승차총승객수"
STR_2 = str(i) + "시하차총승객수"
seoul_bus_stop_commute = seoul_bus_stop_commute.drop([STR, STR_2], axis = 1 )
seoul_bus_stop_commute

컬럼이 보기 편해졌다. 그리고 이제 행을 압축시키려고 한다.
데이터는 2019~2022년 10월의 데이터만을 가지고 사용하기로 했다.
그러기 위해서는 연도와 사용월 데이터가 필요했다.
# 연도 컬럼을 생성하자
seoul_bus_stop_commute = seoul_bus_stop_commute.astype({'사용년월' : 'string'})타입을 먼저 변환한다 (사용년월컬럼이 object형이더라)
seoul_bus_stop_commute["연도"] = seoul_bus_stop_commute["사용년월"].str[:4]
seoul_bus_stop_commute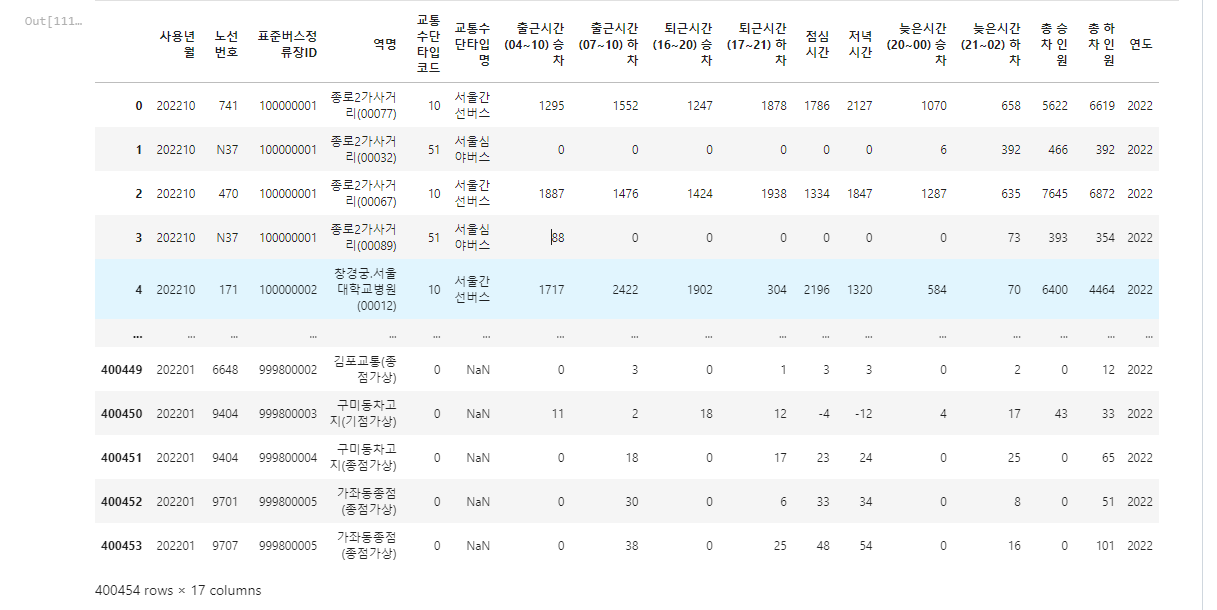
# 월칼럼도 만들어주고 컬럼의 위치를 바꿔주었다.
seoul_bus_stop_commute['월'] = seoul_bus_stop_commute['사용년월'].str[4:]
seoul_bus_stop_commute = seoul_bus_stop_commute.drop('사용년월', axis = 1 )
seoul_bus_stop_commute = seoul_bus_stop_commute[['노선번호','표준버스정류장ID','역명', '연도', '월', '총 승차 인원', '총 하차 인원', '출근시간(04~10) 승차', '출근시간(07~10) 하차',
'퇴근시간(16~20) 승차', '퇴근시간(17~21) 하차', '늦은시간(20~00) 승차', '늦은시간(21~02) 하차', '점심시간','저녁시간']]

여기까지 1차 가공을 진행한다.
여기서 잠깐 다른 길로 센다.
데이터 전처리를 하던 중 든 생각이 정류장 ID별로 value_counts()를 하면
정류장에 몇대의 버스노선이 지나가는지 구할 수 있다.
(이거 대박이잖아?) 이런 생각에 바로 진행했다.
(새로운 쥬피터 노트북이기 때문에 변수명이 바뀐다.)
seoul_bus_stop_commute -> bus_2022
bus_2022[bus_2022['월'].isin([1])]['표준버스정류장ID'].value_counts()
오오? 그러면 일단 원본 데이터에서 1월의 데이터만 가져와보자.
(자료는 2022년의 데이터이니까)
bus_2022_list = []
for i in range(1,12):
bus_2022_list.append(bus_2022[bus_2022['월'].isin([i])])
bus_2022_list[0]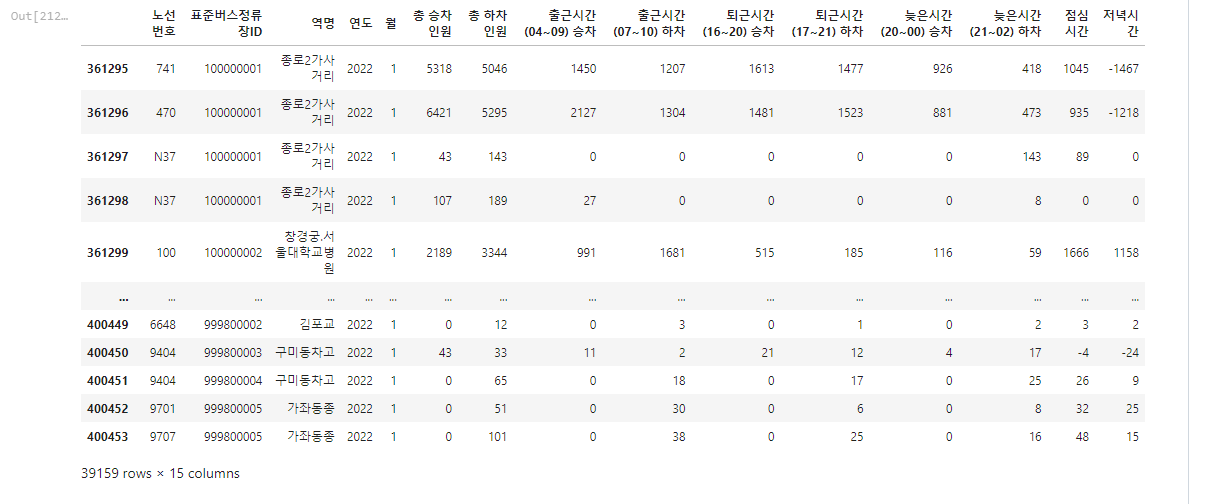
그러면 value_counts()를 컬럼으로 만들고 표준버스정류장 ID를 또 컬럼으로 가지게 하자.
bus_route_2022_1_list = bus_2022_list[9].drop_duplicates(['표준버스정류장ID'])
bus_route_2022_1_list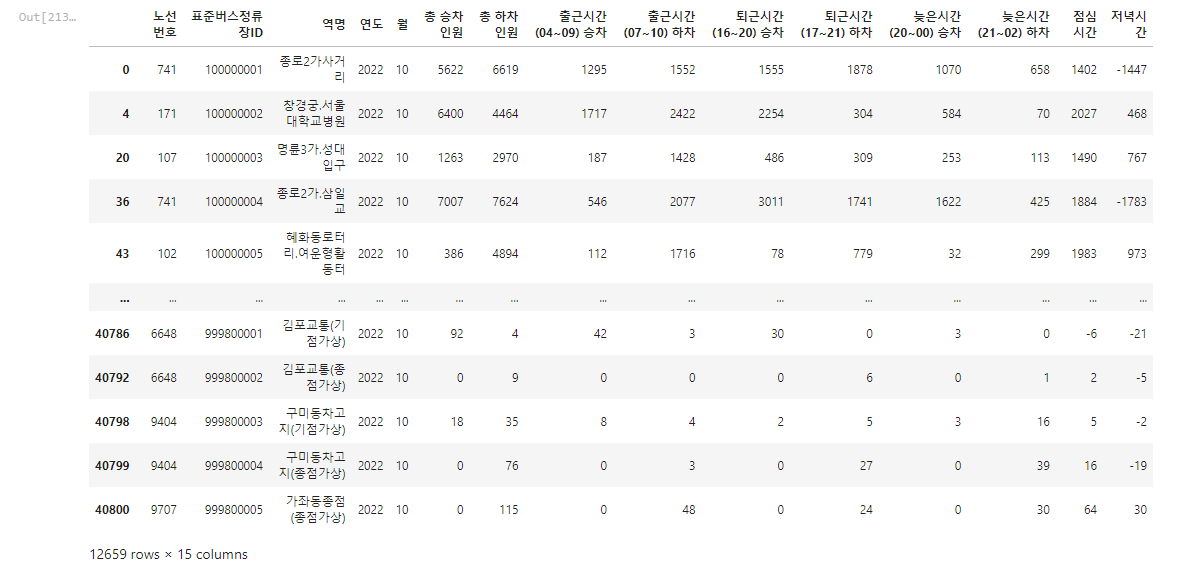
그냥 표준버스정류장ID와 중복되는 행을 모두 삭제하면 된다.
bus_route_count = pd.DataFrame(bus_2022[bus_2022['월'].isin([1])]['표준버스정류장ID'].value_counts())
bus_route_count = bus_route_count.reset_index()
bus_route_count.rename(columns={bus_route_count.columns[1]: "환승 가능한 버스의 수"}, inplace=True)bus_route_count.rename(columns={bus_route_count.columns[0]: "표준버스정류장ID"}, inplace=True)
bus_route_count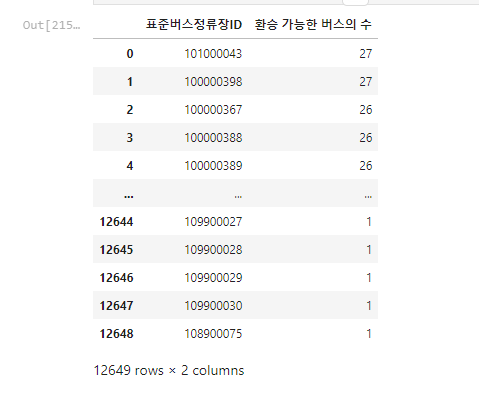
그러면 이렇게 가공하고
아까 중복자료를 지웠던 데이터프레임에서 역명, 표준버스정류장 ID만 분리한다.
bus = pd.DataFrame(bus_route_2022_1_list[['역명', '표준버스정류장ID']])
bus
위의 두 개의 데이터 프레임을 병합하면 된다.
bus_route_count =pd.merge(bus_route_count, bus, left_on='표준버스정류장ID', right_on='표준버스정류장ID', how='inner')
bus_route_count
그러면 정류장별 환승가능 버스의 수를 구할 수 있다.
다시 원본으로 돌아와서(사진은 2019년으로 되어있지만 2022와 크게 다르지 않다)
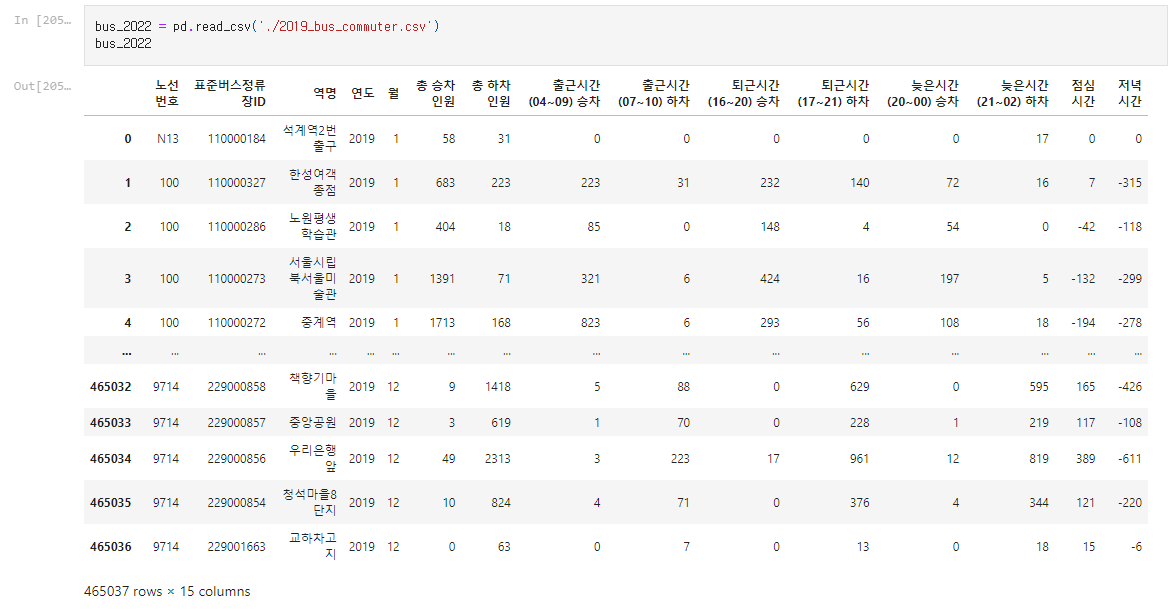
bus_2022 = bus_2022.drop(['노선번호'], axis=1)
bus_2022조금 고민을 많이했다.노선번호가 필요할까?
굳이? 라는 생각이 바로 던져버렸다. 우리가 체크하고 싶은건 상권의 교통인프라이기 때문이다.
물론 어떤 사람은 다양한 지역으로 갈 수 있는 것을 좋은 교통인프라라고 할 수 있다.
그러나 내가 원하는 것은 상권에 얼마나 많은 사람이 몰리는지, 그래서 교통인프라는 충분한지? 이기 때문에 버렸다.
bus_2022_10 = bus_2022[bus_2022['월'].isin([10])]
그 자료를 10월의 자료만 따로 분리한다.

여기서 표준버스정류장ID 로 합으로 피벗하면 정류장별 승하차 인원이 구해진다.
bus_2022_10_data_pivot = bus_2022_10.pivot_table(bus_2022_10, index=["표준버스정류장ID"], aggfunc = [np.sum] )
bus_2022_10_data_pivot
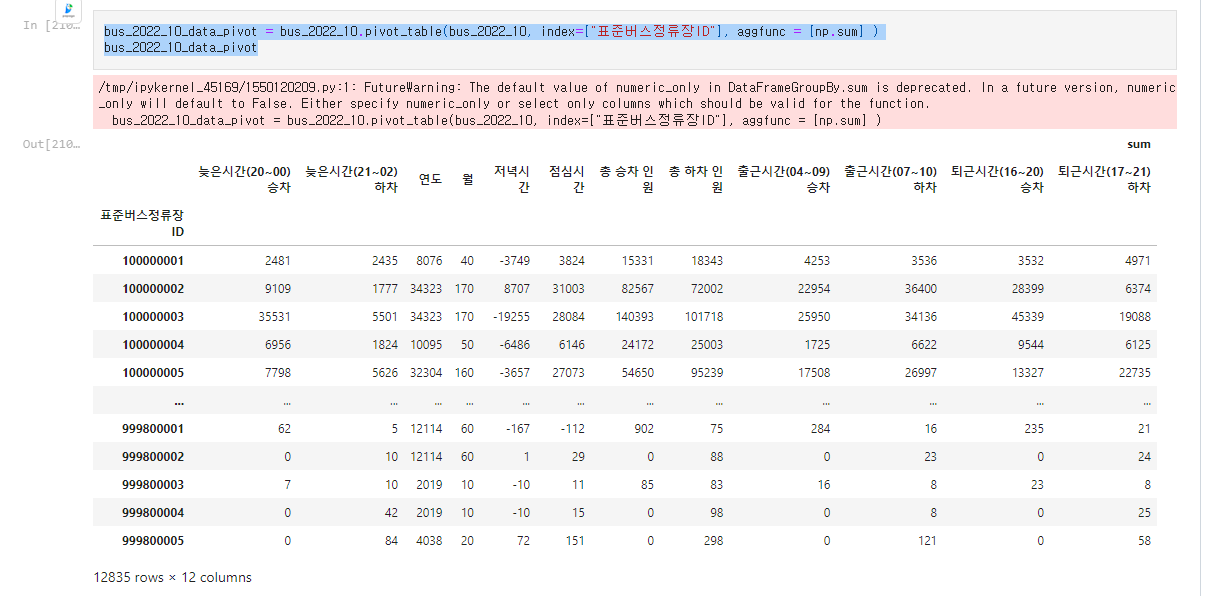
피벗을 한 후 2중 인덱스를 풀어주고 이름을 변경하면 된다.
bus_2022_10_data_pivot.columns = ['/'.join(col) for col in bus_2022_10_data_pivot.columns]
bus_2022_10_data_pivot

bus_2022_10_wow=bus_2022_10_data_pivot
bus_2022_10_wow피벗을 하고 나면 데이터가 꼬일 가능성이 크기 때문에 새로운 변수로 선언해주자.
bus_2022_10_wow = bus_2022_10_wow.drop(['sum/연도', 'sum/월'], axis = 1)
bus_2022_10_wow피벗이 합연산이기 때문에 이상해진 연도, 월을 버리자.
(어차피 2022년 10월 이니까)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[0]: "늦은시간(20~00) 승차"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[1]: "늦은시간(21~02) 하차"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[2]: "저녁시간"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[3]: "점심시간"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[4]: "총 승차 인원"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[5]: "총 하차 인원"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[6]: "출근시간(04~09) 승차"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[7]: "출근시간(07~10) 하차"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[8]: "퇴근시간(16~20) 승차"}, inplace=True)
bus_2022_10_wow.rename(columns={bus_2022_10_wow.columns[9]: "퇴근시간(17~21) 하차"}, inplace=True)
그리고 컬럼명을바꿔준다.

이 파일을 정류장별 버스노선의 개수 파일을 가져와 merge 시킵시다.
bus_route_2022 = pd.read_csv('./2019~2022년 버스정류장 환승가능버스 데이터/2019_10_bus_route.csv')
bus_route_2022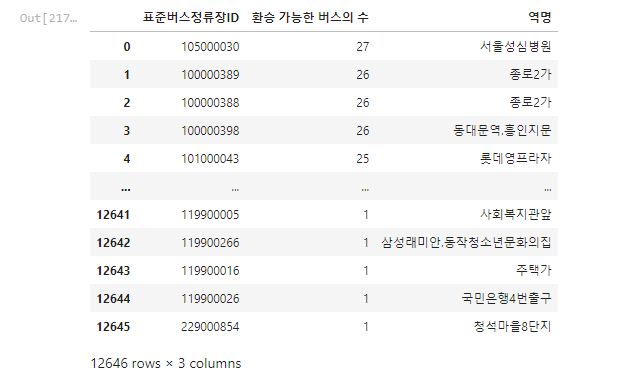
bus_data_2022_10 =pd.merge(bus_2022_10_wow, bus_route_2022, left_on='표준버스정류장ID', right_on='표준버스정류장ID', how='inner')
bus_data_2022_10
컬럼을 정리하면 버스데이터는 끝이납니다.
bus_data_2022_10 = bus_data_2022_10[['연도', '월', '표준버스정류장ID','역명', '환승 가능한 버스의 수' , '총 승차 인원', '총 하차 인원', '출근시간(04~09) 승차', '출근시간(07~10) 하차',
'퇴근시간(16~20) 승차', '퇴근시간(17~21) 하차', '늦은시간(20~00) 승차', '늦은시간(21~02) 하차', '점심시간','저녁시간']]

이걸 2019~2022년까지 반복했습니다.
아니죠 하나가 더있습니다.
서울시 버스정류장별 위치데이터
http://data.seoul.go.kr/dataList/OA-15067/S/1/datasetView.do#
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
이걸 추가해줘야합니다.
조금 복잡합니다.
파일의 형식이 다다름니다. 그러니 신중하게 파일을 만드셔야합니다.
#2022 , 2021년의 경우
bus_location_2022_10 = pd.read_csv('./2022_bus_location.csv', encoding='EUC-KR')
bus_location_2022_10 = bus_location_2022_10.drop(['정류소명', 'ARS-ID'], axis=1)
#us_location_2022_10 = pd.read_excel('./2021_bus_location.xlsx')
#2019년의 경우 바뀜
#bus_location_2022_10 = bus_location_2022_10.drop(['정류장명', 'ARSID'], axis=1)
#bus_location_2022_10 = bus_location_2022_10.drop(['정류장명', 'ARS-ID', '비고'], axis=1)
bus_location_2022_10엑셀의 경우 엑셀로 읽고 데이터프레임을 보고
이 3개 컬럼만 남기고 삭제한다.
bus_data_2022_10 = pd.read_csv('./bus_data_2022_10_final.csv')
bus_data_2022_10이 컬럼을 불러와서
병합을 진행합니다.
#2022년의 경우 NODE_ID
bus_data_2022_10_insert =pd.merge(bus_data_2022_10, bus_location_2022_10, left_on='표준버스정류장ID', right_on='NODE_ID', how='inner')
bus_data_2022_10_insert

bus_data_2022_10_insert = bus_data_2022_10_insert.drop(['NODE_ID'], axis=1)
bus_data_2022_10_insert
표준버스정류장 ID 컬럼이 중복되니까 삭제해줍시다.

그러면 버스데이터 가공은 끝이납니다.
'취업전 프로젝트 > TEAM_서울시 교통 인프라 분석' 카테고리의 다른 글
| 6. 서울시 승용차 평균속도 데이터 가공 (0) | 2022.11.19 |
|---|---|
| 5. 서울시 승용차 평균속도 데이터를 통해 가공하고 네비게이션용 지도를 그려보자. (1) | 2022.11.19 |
| 4. (EDA_프로젝트) 서울시 지하철 데이터로 지하철 노선도를 그려보자. (1) | 2022.11.14 |
| 3. (EDA_프로젝트) 서울시 지하철 데이터를 수집하고 가공하자. (1) | 2022.11.14 |
| 1. (EDA_프로젝트) 주제 선정하기 (1) | 2022.11.13 |