팀원의 데이터가공내용을 정리하여 올리는 글입니다.
제가 만든 것이 아니기 때문에 설명이 빈약합니다.

데이터 출처
서울시 주차장 확보율 통계
서울시 주차장 확보율 통계> 데이터셋> 공공데이터 | 서울열린데이터광장 (seoul.go.kr)
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
서울시 주차장 통계
서울시 주차장 (동별) 통계> 데이터셋> 공공데이터 | 서울열린데이터광장 (seoul.go.kr)
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
서울시 불법주정차 단속 현황
통계자료 < 교통 < 서울특별시 (seoul.go.kr)
통계자료
통계자료
news.seoul.go.kr
우선 통계 데이터를 정리하고 가공합니다.
import pandas as pd
raw = pd.read_csv('../data/주차장+확보율_20221105174339.csv', encoding='utf-8')
raw
#2021년 주차장 확보율
df = pd.DataFrame(raw,columns=['자치구별(2)','2021', '2021.1', '2021.2'])
df
2021년의 데이터만 뽑아냅니다.
df.rename(columns={'자치구별(2)': '구',
'2021': '자동차등록대수(대)',
'2021.1': '주차면수(면수)',
'2021.2': '주차장확보율(%)'},inplace=True)
df.drop([0,1],inplace=True)
df컬럼 이름을 알아보기 쉽게 정리합니다.

df.set_index('구',inplace=True)
df
인덱스를 구로 바꿉니다.
이제 이를 시각화해봅시다.
import matplotlib.pyplot as plt
%matplotlib inline
plt.rc('font', family='NanumGothicCoding')
from matplotlib.colors import ListedColormap
color_step= ["#e74c3c", "#2ecc71", "#95a5a6", "#2ecc71", "#3498db", "#3498db"]
my_cmap= ListedColormap(color_step)
import numpy as np
fp1 = np.polyfit(df["자동차등록대수(대)"], df["주차면수(면수)"],1)
fp1
f1 = np.poly1d(fp1)
fx = np.linspace(50000, 250000, 100)
df["오차"] = df["주차면수(면수)"] - f1(df["자동차등록대수(대)"])
df_sort_f = df.sort_values(by="오차", ascending=False)
df_sort_t = df.sort_values(by="오차", ascending=True)
df["오차"] = df["주차면수(면수)"] - f1(df["자동차등록대수(대)"])
df_sort_f = df.sort_values(by="오차", ascending=False)
df_sort_t = df.sort_values(by="오차", ascending=True)
plt.figure(figsize=(14,10))
plt.scatter(df["자동차등록대수(대)"],df["주차면수(면수)"], c=df["오차"], s = 50, cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3,color="grey")
for n in range(3):
plt.text(
df_sort_f["자동차등록대수(대)"][n]*1.02,
df_sort_f["주차면수(면수)"][n]*0.98,
df_sort_f.index[n],
fontsize=15)
plt.text(
df_sort_t["자동차등록대수(대)"][n]*1.02,
df_sort_t["주차면수(면수)"][n]*0.98,
df_sort_t.index[n],
fontsize=15)
plt.xlabel("자동차등록대수(대)")
plt.ylabel("주차면수(면수)")
plt.colorbar()
plt.grid()
plt.show();
(제가 시각화가 너무 약해서 해석하기 어렵넹)
자동차 등록대수 대비 주차면수를 시각화했습니다.

가장 주차자리를 찾기 편한 구는 강남구, 종로구, 중구로 나타나며, 가장 주차자리를 찾기 힘든 구는 양천구, 노원구, 강동구로 나타납니다.
이번엔 서울시 공영주차장 데이터를 분석합니다.
raw_park = pd.read_csv('../data/서울시 공영주차장 안내 정보.csv',encoding='euc-kr')
raw_park

##필요한 컬럼만 적용
park = pd.DataFrame(raw_park, columns=['주차장명','주소','총 주자면', '유무료구분명', '토요일 유,무료 구분명','공휴일 유,무료 구분명', '주차장 위치 좌표 위도','주차장 위치 좌표 경도'])
park.rename(columns={'총 주자면': '총 주차면',
'유무료구분명': '평일',
'토요일 유,무료 구분명': '토요일',
'공휴일 유,무료 구분명': '공휴일',
'주차장 위치 좌표 위도': '위도',
'주차장 위치 좌표 경도': '경도'}, inplace = True)
park
필요한 컬럼만 분리하고 컬럼의 이름을 수정합니다.
gu = []
for each in park['주소']:
gu.append(each.split()[0])
park['구'] = gu
park

시각화에 용의하게 구만 분리합니다
## 주차장 별 주차면 sum
import numpy as np
park_temp = park[['주차장명', '총 주차면']]
park_pivot = pd.pivot_table(park_temp, index=["주차장명"], aggfunc = np.sum )
park_pivot
주차장별 주차면을 모두 합합니다. 피벗을 이용해서
park = park.drop_duplicates(['주차장명'])
park = park.drop(['주소','총 주차면'], axis = 1)
park
정리하고 나서
park_result = pd.merge(park, park_pivot, left_on='주차장명', right_on='주차장명', how='inner')
park_result머지시켜 구별, 주차장별로 구합니다.

park_result_gu = park_result.pivot_table(index=['구'], values=['총 주차면'], aggfunc = np.sum)
park_result_gu.sort_values(by='총 주차면',ascending=False)
park_result_gu["총 주차면"].sum()
park_result_gu["총 주차면"].sort_values().plot(kind="barh", grid=True, title="공영주차장 주차면이 많은 구", figsize=(10,10));
공영주차장 주차면으로 순위로 정렬하면
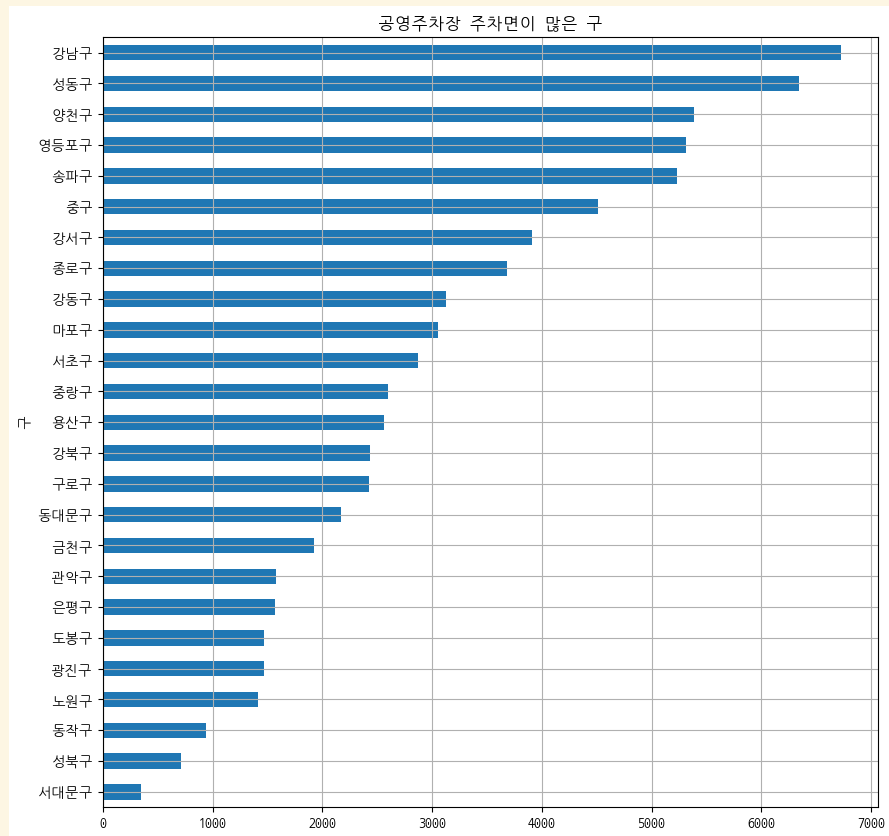
df["공영주차장 주차면수"] = park_result_gu["총 주차면"]
df["공영주차장 비율"] = df["공영주차장 주차면수"] / df["주차면수(면수)"] * 100
df
fp1 = np.polyfit(df["주차면수(면수)"], df["공영주차장 주차면수"],1)
f1 = np.poly1d(fp1)
fx = np.linspace(50000, 500000, 100)
df["공영주차장 오차"] = df["공영주차장 주차면수"] - f1(df["주차면수(면수)"])
df_sort_f = df.sort_values(by="공영주차장 오차", ascending=False)
df_sort_t = df.sort_values(by="공영주차장 오차", ascending=True)
plt.figure(figsize=(14,10))
plt.scatter(df["주차면수(면수)"],df["공영주차장 주차면수"], c=df["공영주차장 오차"], s = 50, cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3,color="grey")
for n in range(3):
plt.text(
df_sort_f["주차면수(면수)"][n]*1.02,
df_sort_f["공영주차장 주차면수"][n]*0.98,
df_sort_f.index[n],
fontsize=15)
plt.text(
df_sort_t["주차면수(면수)"][n]*1.02,
df_sort_t["공영주차장 주차면수"][n]*0.98,
df_sort_t.index[n],
fontsize=15)
plt.xlabel("주차면수(면수)")
plt.ylabel("공영주차장 주차면수")
plt.colorbar()
plt.grid()
plt.show();
공영주차장의 주차면수 대비 주차면수가 얼마나 있는지

성동구 양천구 중구가 공영주차장의 비율이 높고
서대문구 성북구 노원구의 공영주차장 비율이 낮았습니다.
이번에는 공영주차장의 유료, 무료 경향을 알아봅시다.
import seaborn as sns
f, ax = plt.subplots(1,3, figsize=(14,6))
sns.set_palette("Set2")
park_result["평일"].value_counts().plot.pie(explode=[0, 0.02], ax=ax[0], autopct='%.1f%%')
ax[0].set_title('평일')
ax[0].set_ylabel('');
park_result["토요일"].value_counts().plot.pie(explode=[0, 0.02], ax=ax[1], autopct='%.1f%%')
ax[1].set_title('토요일')
ax[1].set_ylabel('');
park_result["공휴일"].value_counts().plot.pie(explode=[0, 0.02], ax=ax[2], autopct='%.1f%%')
ax[2].set_title('공휴일')
ax[2].set_ylabel('');
park_result_station = park_result[["주차장명", "평일", "토요일", "공휴일", "구", "총 주차면"]]
park_result_station
park_result_temp = park_result_station.pivot_table(index=['구'], columns=['평일','토요일','공휴일'],aggfunc=np.sum, fill_value=0)
park_result_temp
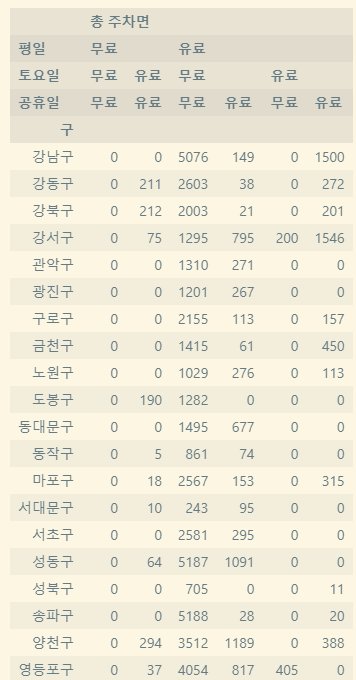
park_result_temp.columns=park_result_temp.columns.droplevel([0])
park_result_temp.columns
tmp = park_result_temp.columns.get_level_values(0) + park_result_temp.columns.get_level_values(1) + park_result_temp.columns.get_level_values(2)
park_result_temp.columns = tmp
park_result_norm = park_result_temp[tmp] / park_result_temp[tmp].max()
park_result_norm["주차비"] = np.mean(park_result_norm[tmp], axis=1)
import seaborn as sns
park_result_norm_sort = park_result_norm.sort_values(by='주차비', ascending=False)
plt.figure(figsize = (10,10))
sns.heatmap(park_result_norm_sort[tmp], annot=True, fmt='f', linewidths=5, cmap='RdPu')
plt.title('정규화된 공영주차장 유/무료 비율(평일,토요일,공휴일)')
plt.autoscale()
plt.tight_layout(pad=5)
plt.show()

공영주차장 유/무료 비율을 구할 수 있습니다.
이제 서울시 지도에 시각화를 해봅시다.
지역별 공영주차장 주차면
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
my_map = folium.Map(location=[37.5502,126.982], zoom_start = 11, tiles='OpenStreetMap')
my_map.choropleth(
geo_data=geo_str,
data=park_result_gu['총 주차면'],
columns=[park_result_gu.index, park_result_gu['총 주차면']],
fill_color='PuRd',
key_on="feature.id",
fill_opacity=0.7,
line_opacity=0.2,
legend_name="지역별 총 주차면",
)
folium.GeoJson(
geo_str,
style_function = lambda x: {'fillColor':'#00000000',
'color':'black',
'weight' :'2'}
).add_to(my_map)

지역별 유/무료 공영주차장 위치
mapping = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='OpenStreetMap')
for idx, row in park_result.iterrows():
try:
if row["평일"] == "무료":
folium.Marker([row["위도"], row["경도"]], popup=row["주차장명"],
icon=folium.Icon(color="blue")).add_to(mapping)
else:
folium.Marker([row["위도"], row["경도"]], popup=row["주차장명"],
icon=folium.Icon(color="red")).add_to(mapping)
except:
print(row["주차장명"])
folium.GeoJson(
geo_str,
style_function = lambda x: {'fillColor':'#00000000',
'color':'black',
'weight' :'2'}
).add_to(mapping)
mapping

이번엔 서울시 구별 주정차 단속현황입니다.
뷰리풀숲을 사용했습니다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
## 서울특별시 교통위반단속 통계자료
url = "https://news.seoul.go.kr/traffic/archives/35239"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
import re
gu = []
_2017 = []
_2018 = []
_2019 = []
_2020 = []
_2021 = []
for n in range(25):
tmp = soup.find("table").find_all("tr")[n+3].get_text()
tmp_string = re.split(("\n\n|\r\n"), tmp)
tmp
print(tmp_string)
이 데이터를 데이터프레임으로 만들어버립시다.
import re
gu = []
_2017 = []
_2018 = []
_2019 = []
_2020 = []
_2021 = []
for n in range(25):
tmp = soup.find("table").find_all("tr")[n+3].get_text()
tmp_string = re.split(("\n\n|\r\n"), tmp)
if tmp_string[1] == '중구':
gu.append(tmp_string[1])
else:
gu.append(tmp_string[1] + '구')
_2017.append(re.split(("\n"),tmp_string[2])[1])
_2018.append(re.split(("\n"),tmp_string[3])[1])
_2019.append(re.split(("\n"),tmp_string[4])[1])
_2020.append(re.split(("\n"),tmp_string[5])[1])
try:
_2021.append(re.split(("\n"),tmp_string[6])[1])
except:
_2021.append(tmp_string[6])
data = {"구": gu, "2017년":_2017, "2018년":_2018, "2019년":_2019, "2020년":_2020, "2021년":_2021}
park_illegal = pd.DataFrame(data)
park_illegal.set_index('구', inplace=True)
park_illegal

tmp = park_illegal.columns
park_illegal_norm = park_illegal[tmp] / park_illegal[tmp].max()
park_illegal_norm
park_illegal_norm["평균"] = np.mean(park_illegal_norm[tmp], axis=1)
park_illegal_norm
park_illegal_norm_sort = park_illegal_norm.sort_values(by='평균', ascending=False)
plt.figure(figsize=(13,10))
sns.heatmap(park_illegal_norm_sort[tmp], annot=True, linewidths=.5,cmap='RdPu')
plt.title('2017년부터 2021년 서울시 구별 주정차단속 건 수')
plt.autoscale()
plt.tight_layout(pad=5)
plt.show()히트맵을 그려보면

행정구역별 위도경도 좌표를 가져왔습니다.
excel = pd.read_excel('../data/행정구역별_위경도_좌표.xlsx')
seoul_gps = excel[excel["읍면동/구"].isnull()].drop([0])
seoul_gps = seoul_gps[["시군구","위도","경도"]]
seoul_gps.rename(columns={'시군구':'구'},inplace=True)
seoul_gps.set_index('구', inplace=True)
seoul_gps
result = pd.merge(park_illegal, seoul_gps, left_on='구', right_on='구', how='inner')
result
오.. 컬럼과 인덱스를 교체하는 문법이 있구나..
처음알아
park_illegal.t = park_illegal.transpose()
park_illegal.t
import plotly.express as px
fig = px.line(park_illegal.t,title='주정차 단속건수')
fig.show()

주정차 단속건수의 흐름을 알 수 있다.
해당 코드를 이용해서 불법주정차 단속이 어떻게 변화하는지 확인해볼 수 있다.
from folium import plugins
from folium.plugins import HeatMapWithTime
import time
time_series =['2017','2018','2019','2020','2021']
for year in time_series:
result[year+'년'] = result[year+'년']/max(result[year+'년'])
heat_data_temp = [[[row['위도'],row['경도'],row[year+'년']] for index, row in result.iterrows()] for year in time_series]
m = folium.Map([37.55,126.9], zoom_start=10.5, control_scale=True)
hm = plugins.HeatMapWithTime(heat_data_temp, index=[year for year in time_series], auto_play=True, radius=60,
max_opacity=.5)
hm.add_to(m)
m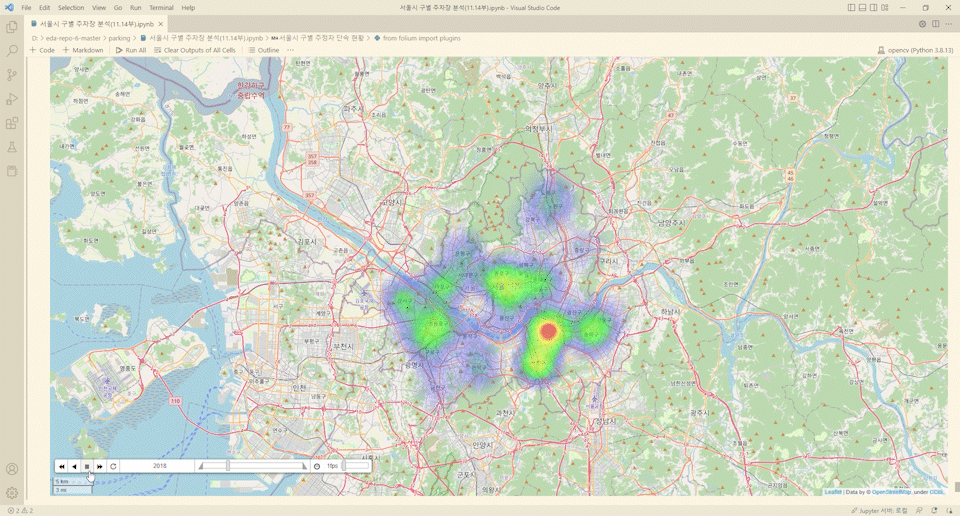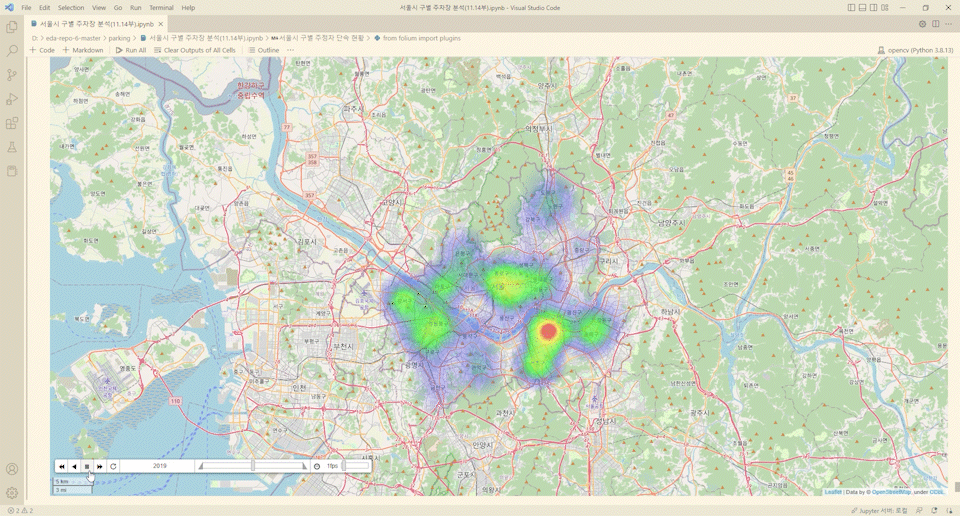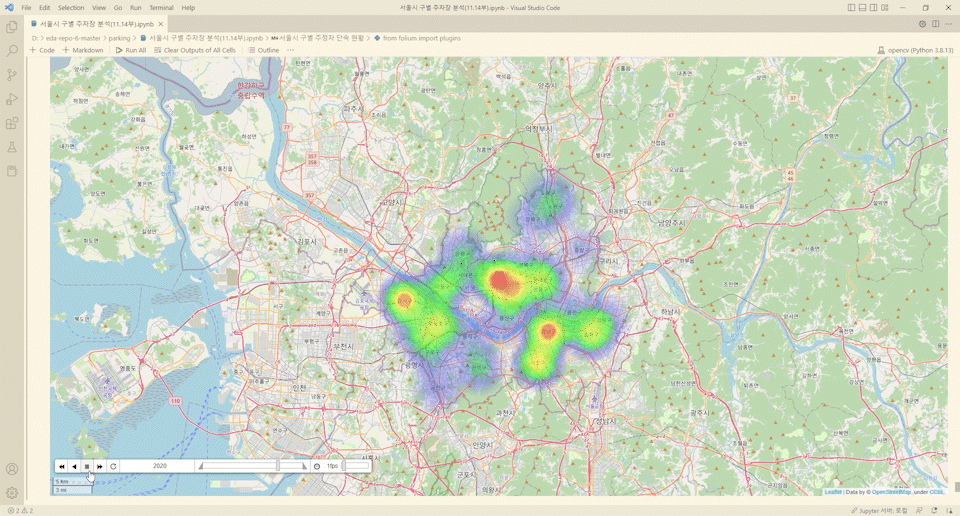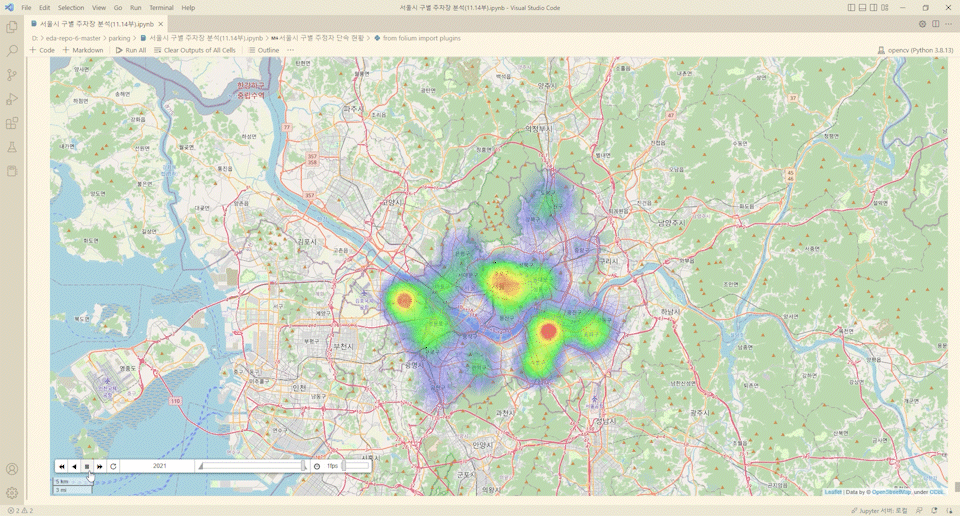
와.. ㄷㄷ..
'취업전 프로젝트 > TEAM_서울시 교통 인프라 분석' 카테고리의 다른 글
| 12. 프로젝트를 마치며 (0) | 2022.11.20 |
|---|---|
| 10. 대중교통, 상권, 도로 데이터를 모두 시각화해보자. (0) | 2022.11.20 |
| (팀원) 9. 서울시 도로율 분석 및 시각화 (0) | 2022.11.20 |
| (팀원) 8. 서울시와 뉴욕시의 교통사고 데이터 분석 및 시각화 (0) | 2022.11.20 |
| 7. 서울시 상권데이터를 분석하자. (0) | 2022.11.19 |