이전 글에서 이어지는 내용으로
상권이 있으면 교통인프라가 좋을까의 최종 글입니다.
경고
이 글은 코드가 길고 설명이 빈약합니다.
결과론적으로 설명을 하고 있으며 코드를 해석하기 힘들다면 이해하기 어려울 수 있습니다.

import folium
import pandas as pd
import numpy as np
from haversine import haversine
from tqdm import tqdm
지도에 그림을 많이 그릴 예정입니다.
market_region = pd.read_csv('./2021상권데이터 최종.csv', encoding='EUC-KR')
market_region상권데이터를 가져옵시다.

이걸 한 번 지도에 표시해봅시다.
폴리움에 원을 그리려고 합니다.
[김영갑 교수의 상권분석과 마케팅 14] 상권과 입지 선택을 위한 분류법 이해하기 (hotelrestaurant.co.kr)
[김영갑 교수의 상권분석과 마케팅 14] 상권과 입지 선택을 위한 분류법 이해하기
상권과 입지를 조사하고 분석하는 과정은 매우 복잡하고 많은 시간이 필요하다. 그래서 급한 의사결정이 필요한 경우에는 경험과 직관에 의존하게 된다. 그리고 실제로 현장에서 조사자의 감각
www.hotelrestaurant.co.kr
1차 상권의 정의는 상권에서 500m 범위에 있는가 입니다.
그렇기에 상권의 위도 경도에 500m의 원을 그립니다.
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
for each in range(len(market_region)):
marker_circle = folium.Circle([market_region['lat'][each], market_region['long'][each]],
radius = 500,
color = 'skyblue',
popup = market_region['상권_코드_명'][each],
fill_color = 'skyblue'
)
marker_circle.add_to(my_map)
my_map
모든 상권을 표시해보니

답이없습니다.
그래서 결국 상권을 규모에 따라 분류를 해야한다고 생각했습니다.
그러기 위해서 가장 중요한 것이 유동인구를 추정하는 것입니다.
우선 팀원에게서 주차장 데이터를 받아왔습니다.
(아마 이 글의 다음 글에서 이야기가 나올 것입니다.)
car = pd.read_csv('./park_state.csv')
car_data = car[['위도', '경도', '총 주차면']]
car_data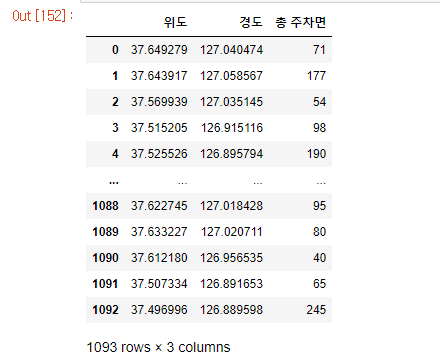
지하철의 데이터를 가공했던 파일도 가져옵니다.
subway = pd.read_csv('./metro_2021_10_location.csv', encoding = "EUC-KR")
subway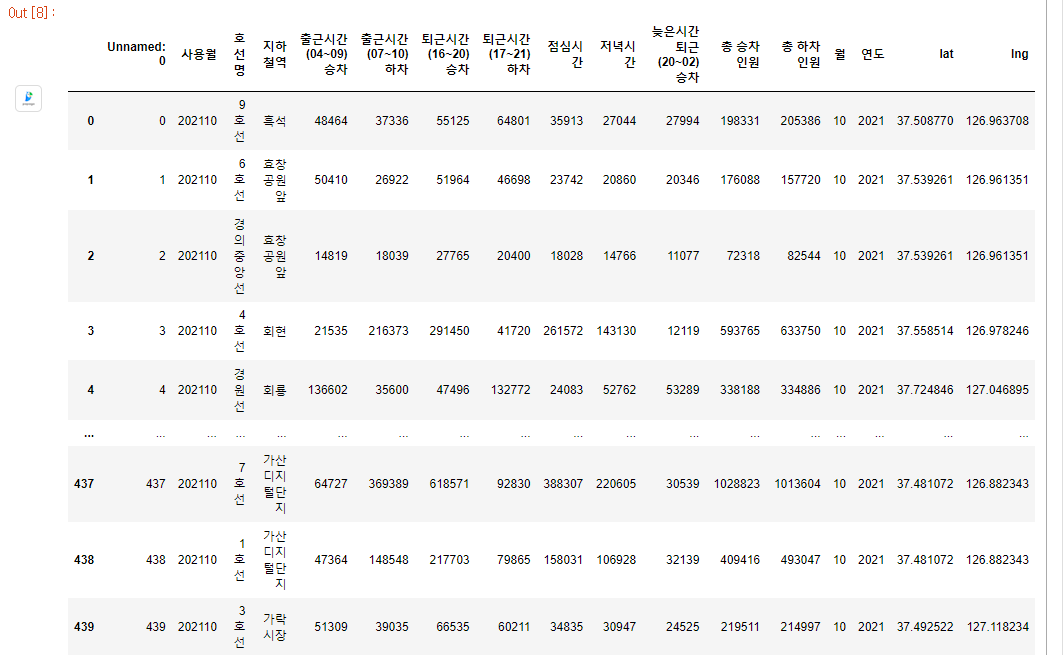
subway_data = subway[['지하철역', '호선명', '총 승차 인원', '총 하차 인원', 'lat', 'lng']]
subway_data
버스 데이터도 가져옵니다.
bus = pd.read_csv('./2022_10_bus_data_final.csv')
bus_data = bus[['좌표X', '좌표Y', '총 승차 인원', '총 하차 인원', '환승 가능한 버스의 수']]
bus_data.rename(columns={bus_data.columns[0]: "X좌표"}, inplace=True)
bus_data.rename(columns={bus_data.columns[1]: "Y좌표"}, inplace=True)
bus.head()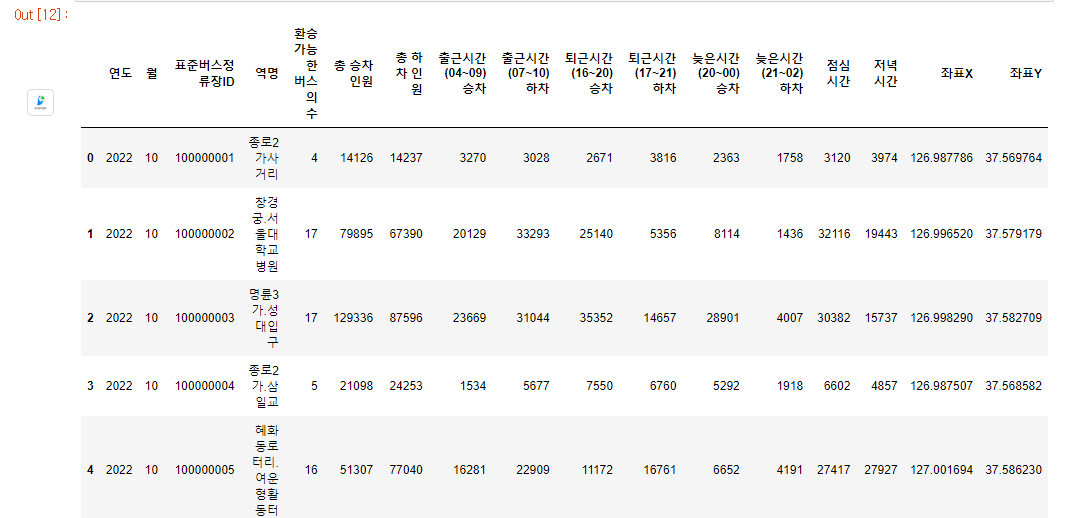
마켓 구역에 다음을 추가합니다.
상권내 모든 주차장에는 사람이 1.5명씩 타고 있다고 가정을 합니다.
market_region_human = market_region[['상권_코드_명', '점포_수', '분기당_매출_금액', '분기당_매출_건수', 'long', 'lat']]
market_region_human['유동인구'] = 0
market_region_human['환승가능한버스노선'] = 0
market_region_human['500m 버스정류장'] = 0
market_region_human['환승가능지하철'] =0
market_region_human['환승가능 호선명'] = ""
market_region_human['500m 지하철역'] = 0
market_region_human이제 상권주변에 유동인구가 몇명이 있는지 지하철역, 버스정류장은 몇곳이 있는지 이런 것을 확인할 것입니다.
조금 복잡한 코드가 나옵니다.
sub_count = 0
bus_count = 0
for i in tqdm(range(len(market_region_human))):
sub_count = 0
bus_count = 0
sub_station = []
sub_station_name = []
hosun = ""
market_region_location = (market_region_human['lat'][i], market_region_human['long'][i])
for each in range(len(bus_data)):
bus_data_location = (bus_data['Y좌표'][each], bus_data['X좌표'][each])
a = haversine(market_region_location, bus_data_location, unit = 'm')
if a < 500:
bus_count = bus_count + 1
market_region_human['유동인구'][i] = market_region_human['유동인구'][i] + bus_data['총 하차 인원'][each]
market_region_human['환승가능한버스노선'][i] = market_region_human['환승가능한버스노선'][i] + bus_data['환승 가능한 버스의 수'][each]
market_region_human['환승가능한버스노선'][i] = market_region_human['환승가능한버스노선'][i] / bus_count
market_region_human['500m 버스정류장'][i] = bus_count
for each in range(len(subway_data)):
subway_data_location = (subway_data['lat'][each], subway_data['lng'][each])
a = haversine(market_region_location, subway_data_location, unit = 'm')
if a < 500:
market_region_human['유동인구'][i] = market_region_human['유동인구'][i] + subway_data['총 하차 인원'][each]
sub_station.append(subway_data["호선명"][each])
if (subway_data["지하철역"][each] not in sub_station_name):
sub_count = sub_count + 1
sub_station_name.append(subway_data["지하철역"][each])
sub_station = list(set(sub_station))
for j in range(len(sub_station)):
hosun = hosun + sub_station[j]
if j+1 != len(sub_station):
hosun = hosun + ';'
market_region_human['환승가능지하철'][i] = len(sub_station)
market_region_human['500m 지하철역'][i] = sub_count
market_region_human['환승가능 호선명'][i] = hosun
market_region_human['유동인구'][i] = (market_region_human['유동인구'][i]) / 31
for each in range(len(car_data)):
car_data_location = (car_data['위도'][each], car_data['경도'][each])
a = haversine(market_region_location, car_data_location, unit = 'm')
if a < 500:
market_region_human['유동인구'][i] = market_region_human['유동인구'][i] + (car_data['총 주차면'][each] * 1.5)원래 코드를 길게 짜는 걸 좋아하다보니
이 코드를 돌면 상권의 전체 유동인구의 수, 환승가능한 버스노선은 몇개, 버스정류장은 몇개, 지하철역은 몇개, 환승가능한 호선은 몇개인지 나옵니다.
연산속도를 신경쓰지 않고 만든 코드이기 때문에 많이 느립니다.
상권의 데이터에 버스, 지하철, 주차장의 모든 위도경도와 위치계산을 하는 단순무식한 알고리즘입니다.
시간은 3~5분정도 걸립니다.
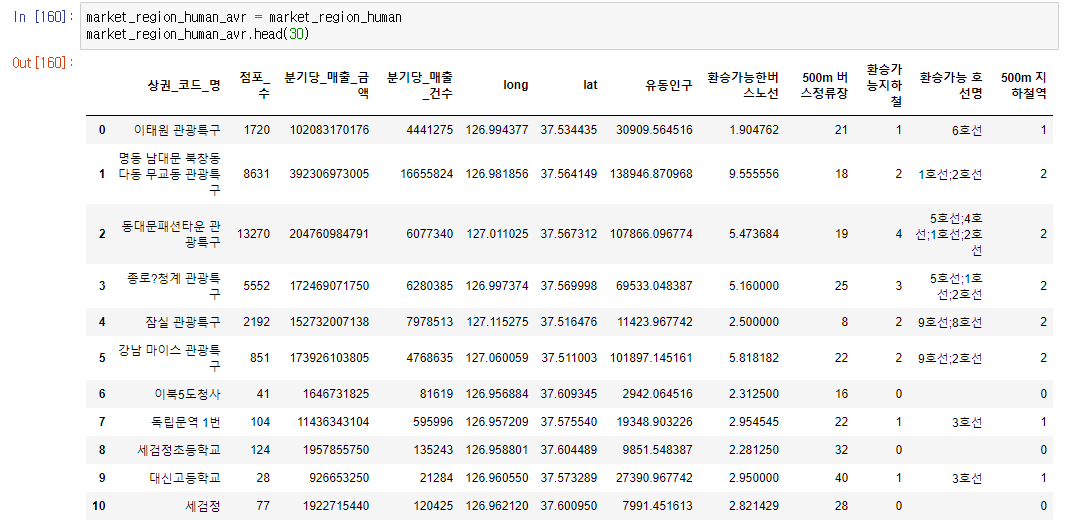
이런 느낌으로 말이죠.
그러면 우리는 여기서 하나를 정의해야합니다.
대형상권은 유동인구가 10만명 이상이거나 일매출이 10억이상인 상권을 말합니다.
중형상권은 유동인구가 2만명 이상인 상권을 말합니다.
그래서 한가지를 추가했습니다.
초대형상권 : 유동인구가 10만명 이상이면서 일매출이 10억원이상인 상권
대형상권 : 유동인구가 10만명 미만이면서 일매출 10억원이상인 상권
중형상권 : 초대형상권과 대형상권을 빼고 100개의 상권이 될때까지의 나머지
그래서 우선은 중형상권만 뽑아서 저장을 합니다.
유동인구는 이렇게 추정합니다.
상권내 지하철역 총하차수
상권내 버스정류장 총 하차수
상권내 주차장의 주차면수 X 1.5 (승용차)
middle_market_region = market_region_human_avr.loc[market_region_human_avr['유동인구'] >= 20000]
middle_market_region
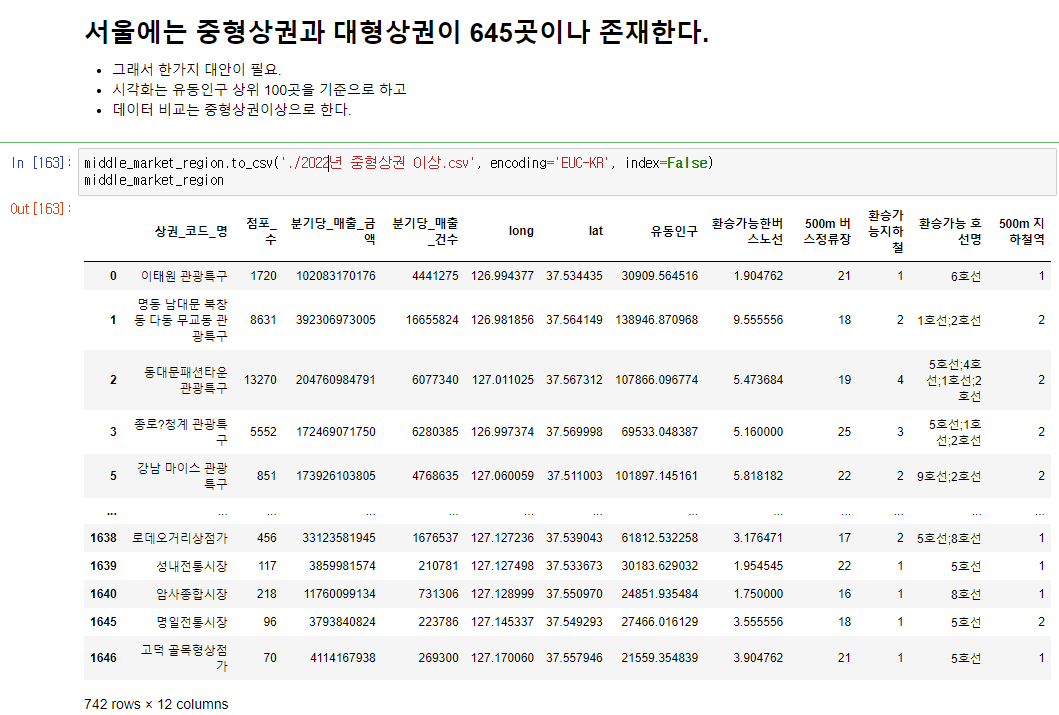
market_2022 = pd.read_csv('./2022년 중형상권 이상.csv', encoding='EUC-KR')
market_2021 = pd.read_csv('./2021년 중형상권 이상.csv', encoding='EUC-KR')
market_2020 = pd.read_csv('./2020년 중형상권 이상.csv', encoding='EUC-KR')
market_2019 = pd.read_csv('./2019년 중형상권 이상.csv', encoding='EUC-KR')
market_anual_list = [market_2019, market_2020, market_2021, market_2022]
자 그러면 이제 다시 시각화를 진행해봅시다.
most_big_anual_list = []
big_anual_list = []
middle_anual_list = []
for i in range(len(market_anual_list)):
most_big_market_region = market_anual_list[i].loc[(market_anual_list[i]['유동인구'] >= 100000)]
most_big_market_region = most_big_market_region.loc[(most_big_market_region['분기당_매출_금액']/91) >= 1000000000]
most_big_market_region["상권규모"] = "특대형상권"
most_big_market_region = most_big_market_region.reset_index()
most_big_anual_list.append(most_big_market_region)
for i in range(len(market_anual_list)):
big_market_region = market_anual_list[i].loc[(market_anual_list[i]['유동인구'] < 100000)]
big_market_region = big_market_region.loc[(big_market_region['분기당_매출_금액']/91) > 1000000000]
big_market_region["상권규모"] = "대형상권"
big_market_region = big_market_region.reset_index()
big_anual_list.append(big_market_region)
for i in range(len(market_anual_list)):
middle_market_region = market_anual_list[i].loc[(market_anual_list[i]['유동인구'] < 100000)]
middle_market_region = middle_market_region.loc[(middle_market_region['분기당_매출_금액']/91) < 1000000000]
middle_market_region["상권규모"] = "중형상권"
middle_market_region = middle_market_region.sort_values(by='유동인구', ascending=False)
middle_market_region = middle_market_region.head(100-len(most_big_anual_list[i])-len(big_anual_list[i]))
middle_market_region = middle_market_region.reset_index()
middle_anual_list.append(middle_market_region)아까 말한대로 중형상권, 대형상권, 초대형상권을 분류합니다.
이 코드는 이전에 블로그에 올린 적이 있습니다.
그걸 조금 손봐서 만든 지하철노선도를 그려주는 코드입니다.
location = pd.read_csv('./metro_2022_10_location.csv', encoding='EUC-KR')
location = location.drop(['사용월', '출근시간(04~09) 승차', '출근시간(07~10) 하차', '퇴근시간(16~20) 승차', '퇴근시간(17~21) 하차'
, '점심시간', '저녁시간', '늦은시간퇴근(20~02) 승차', '총 승차 인원', '총 하차 인원', '월', '연도'], axis=1)
location.rename(columns={location.columns[0]: "0"}, inplace=True)
location = location.drop(['0'], axis=1)
list_df = pd.DataFrame(location['호선명'].value_counts())
list_df = list_df.reset_index()
list_df_list = list_df['index'].to_list()
sub_list = []
for i in list_df_list:
sub_list.append(location[location['호선명'].isin([i])])
for i in range(len(list_df)):
sub_list[i] = sub_list[i].reset_index()
sub_list[i] = sub_list[i].reset_index()
color_list = [ 'purple' , 'green' , 'lightgreen' , 'gray' , 'Orange',
'beige' , 'blue ', 'skyblue', 'lightblue' ,
'lightblue' , 'pink', 'yellow', 'cadetblue' ,
'skyblue', 'darkblue' , 'skyblue', 'blue' ]
sub_list_sort = []
for i in list_df_list:
sub_list_sort.append(sub_list[0][sub_list[0]['level_0'].isin([999999])])
for i in range(len(sub_list)):
su = 0
su_list = []
su_list.append(0)
count = 0
sel = 1
while True:
list_temp = []
start = [sub_list[i]['lat'][su], sub_list[i]['lng'][su]]
for j in range(len(sub_list[i])):
if not(j in su_list):
end = [sub_list[i]['lat'][j], sub_list[i]['lng'][j]]
a = haversine(start, end, unit = 'km')
list_temp.append(a)
else:
list_temp.append(10)
if min(list_temp) > 3:
su = 0
sel = 0
count = count + 1
# 까치산 처럼 갈라지는 곳은 대응못함
else:
tmp = min(list_temp)
index = list_temp.index(tmp)
if sel == 1:
sub_list_temp = sub_list[i][sub_list[i]['level_0'].isin([index])]
sub_list_sort[i] = pd.concat([sub_list_sort[i] , sub_list_temp])
elif sel == 0:
sub_list_temp = sub_list[i][sub_list[i]['level_0'].isin([index])]
sub_list_sort[i] = pd.concat([ sub_list_temp, sub_list_sort[i]])
su_list.append(index)
su = index
if count == 2:
break
if len(su_list) == len(sub_list[i]):
break
# 비상수술
sub_list_sort[11] = pd.concat([sub_list[11][sub_list[11]["지하철역"].isin(["수서"])], sub_list_sort[11]])
sub_list_sort[11] = pd.concat([sub_list[11][sub_list[11]["지하철역"].isin(["복정"])], sub_list_sort[11]])
sub_1 = sub_list[6][sub_list[6]["지하철역"].isin(["구로"])]
sub_1 = pd.concat([sub_list[6][sub_list[6]["지하철역"].isin(["가산디지털단지"])], sub_1])
sub_1 = pd.concat([sub_list[6][sub_list[6]["지하철역"].isin(["독산"])], sub_1])
sub_1 = pd.concat([sub_list[6][sub_list[6]["지하철역"].isin(["금천구청"])], sub_1])
sub_list_sort.append(sub_1)
for i in range(len(sub_list_sort)):
sub_list_sort[i] = sub_list_sort[i].drop(['level_0', 'index'], axis=1)
sub_list_sort[i] = sub_list_sort[i].reset_index()
sub_list_sort[i] = sub_list_sort[i].reset_index()
def make_subway_map(my_map):
for each in range(len(sub_list_sort)):
for i in range(len(sub_list_sort[each])):
if (i+1) != len(sub_list_sort[each]):
start = sub_list_sort[each]['lat'][i], sub_list_sort[each]['lng'][i]
end = sub_list_sort[each]['lat'][i+1], sub_list_sort[each]['lng'][i+1]
location_data = [start, end]
folium.PolyLine(locations=location_data, tooltip='Polyline', color=color_list[each]).add_to(my_map)
그 다음의 코드가 이제
팀원이 서울시를 구별로 보여주었으면 좋겠다 싶어서 가져온 구별로 나눠주는 json파일입니다.
e9t - Overview
data hacker; loves geeks, smiling, learning, community action, people that see the bright side of things - e9t
github.com
출처는 이분의 깃헙입니다.
def gu_line(my_map):
geo_path = './skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
my_map.choropleth(
geo_data=geo_str,
fill_color='PuRd',
key_on="feature.id",
fill_opacity=0,
line_opacity=0.2,
legend_name="구별 도로연장",
)
folium.GeoJson(
geo_str,
style_function = lambda x: {'fillColor':'#00000000',
'color':'black',
'weight' :'1.5'}
).add_to(my_map)
이제 본격적으로 시작합시다.
def make_market_region(most_big_anual_list, big_anual_list, middle_anual_list, my_map):
for each in range(len(middle_anual_list)):
marker_circle = folium.Circle([middle_anual_list['lat'][each], middle_anual_list['long'][each]],
radius = 500,
color = 'white',
popup = middle_anual_list['상권_코드_명'][each],
fill_color = 'beige'
)
marker_circle.add_to(my_map)
for each in range(len(big_anual_list)):
marker_circle = folium.Circle([big_anual_list['lat'][each], big_anual_list['long'][each]],
radius = 500,
color = 'orange',
popup = big_anual_list['상권_코드_명'][each],
fill_color = 'orange'
)
marker_circle.add_to(my_map)
for each in range(len(most_big_anual_list)):
marker_circle = folium.Circle([most_big_anual_list['lat'][each], most_big_anual_list['long'][each]],
radius = 500,
color = 'red',
popup = middle_anual_list['상권_코드_명'][each],
fill_color = 'red'
)
marker_circle.add_to(my_map)상권의 규모별로 색을 그린다고 생각하시면 됩니다.
색이 어떤 것을 의미하는지는 그림을 보고 하는게 빠릅니다.
for i in range(len(market_anual_list)):
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
gu_line(my_map)
make_subway_map(my_map)
make_market_region(most_big_anual_list[i], big_anual_list[i], middle_anual_list[i], my_map)
my_map_list.append(my_map)그래서 만들었던 함수를 총동원해서 2019년~2022년의 상권위치를 표시합니다.
2019년입니다.
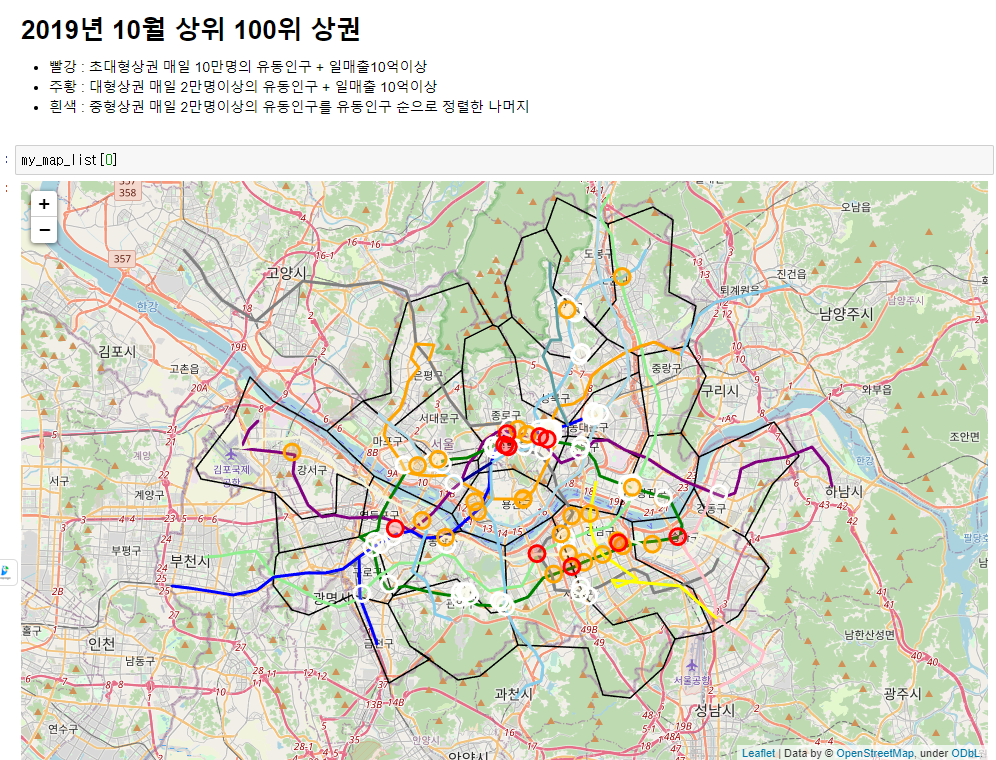
초대형상권의 경우 빨간원입니다. 2019년의 경우 초대형상권이 많았습니다.
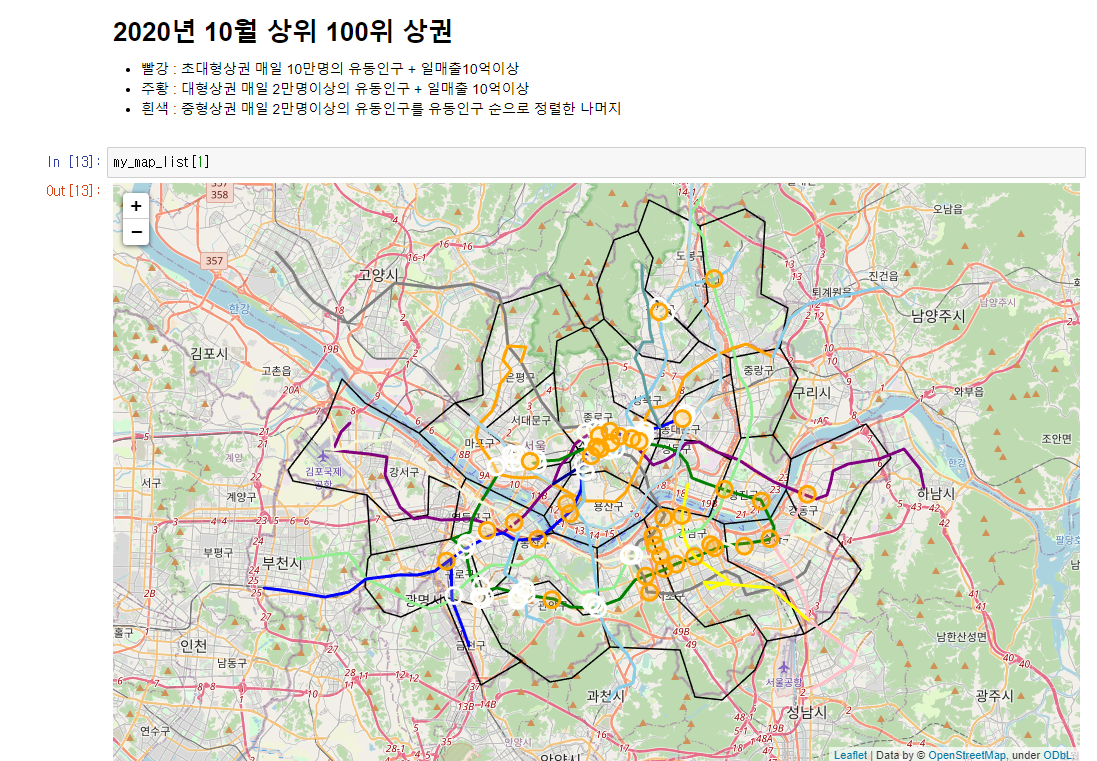
2020년 초대형 상권이 사라집니다.
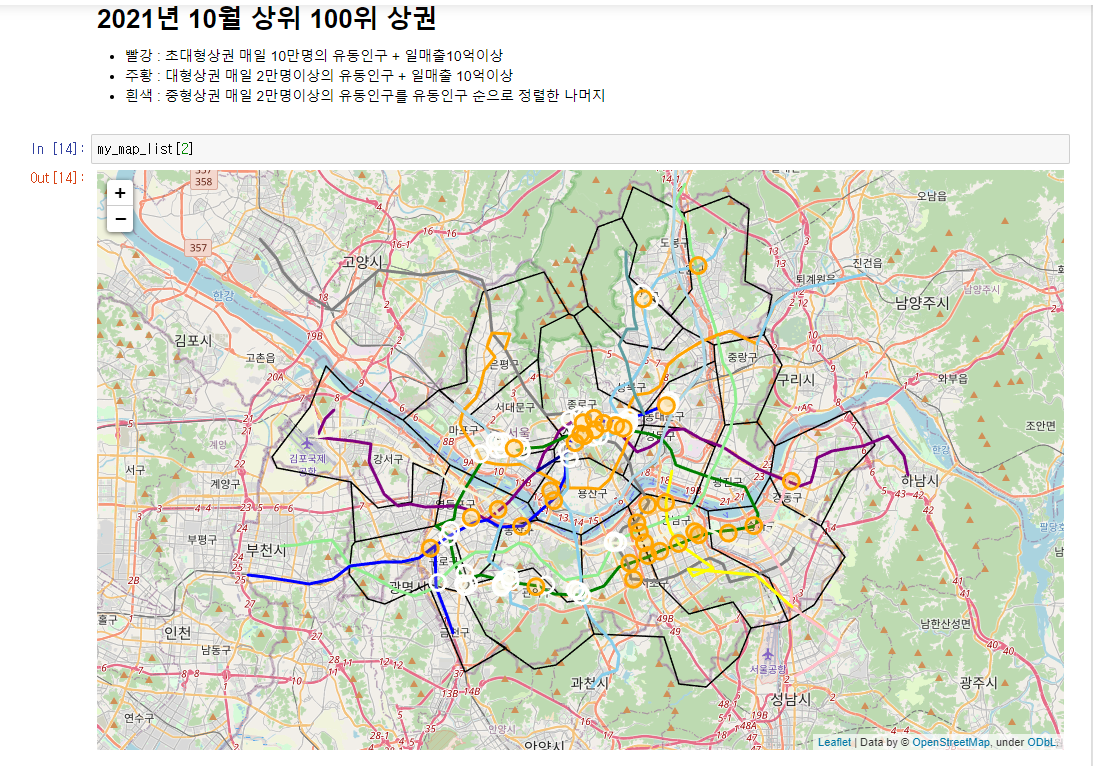
2021년까지 초대형상권은 계속 사라진 상태입니다.
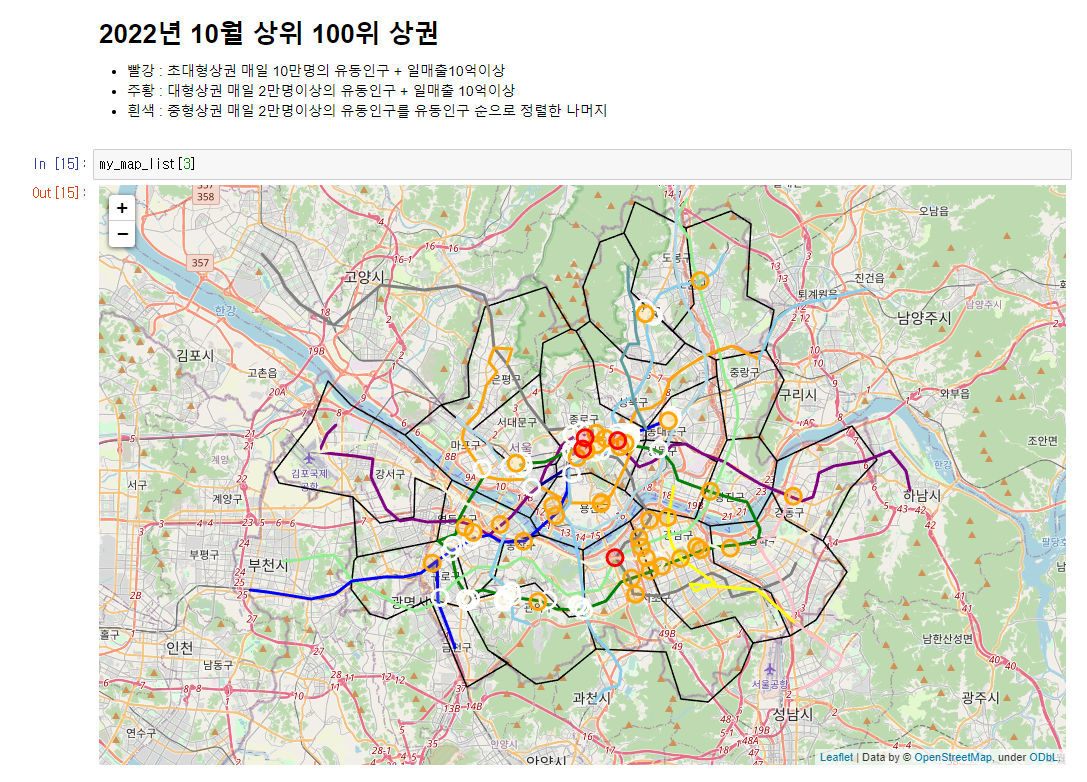
2022년 초대형 상권이 다시 나타납니다.
재미난 결과였습니다. 그래서 궁금했습니다.
원인은 무엇이고
2019년의 초대형상권은 2020년에 모두 대형상권이 되었는지
2022년에 새로 생긴 초대형 상권은 없는지
import matplotlib.pyplot as plt
#import seaborn as sns
%matplotlib inline
middle_market_region_2022_visual = market_2022.loc[(market_2022['유동인구'] < 100000)]
middle_market_region_2022_visual = middle_market_region_2022_visual.loc[(middle_market_region_2022_visual['분기당_매출_금액']/91) < 1000000000]
middle_market_region_2021_visual = market_2021.loc[(market_2021['유동인구'] < 100000)]
middle_market_region_2021_visual = middle_market_region_2021_visual.loc[(middle_market_region_2021_visual['분기당_매출_금액']/91) < 1000000000]
middle_market_region_2020_visual = market_2020.loc[(market_2020['유동인구'] < 100000)]
middle_market_region_2020_visual = middle_market_region_2020_visual.loc[(middle_market_region_2020_visual['분기당_매출_금액']/91) < 1000000000]
middle_market_region_2019_visual = market_2019.loc[(market_2019['유동인구'] < 100000)]
middle_market_region_2019_visual = middle_market_region_2019_visual.loc[(middle_market_region_2019_visual['분기당_매출_금액']/91) < 1000000000]
market_count = pd.DataFrame({'초대형상권' : [len(most_big_anual_list[0]), len(most_big_anual_list[1]),
len(most_big_anual_list[2]), len(most_big_anual_list[3])],
'대형상권' : [len(big_anual_list[0]), len(big_anual_list[1]),
len(big_anual_list[2]), len(big_anual_list[3]),],
'중형상권' : [len(middle_anual_list[0]), len(middle_anual_list[1]),
len(middle_anual_list[2]), len(middle_anual_list[3]),]
}, index = ["2019년", "2020년", "2021년", "2022년"])
market_count = market_count.reset_index()
market_count['중형상권이상의 수'] = market_count['초대형상권'] +market_count['대형상권'] + market_count['중형상권']
#윈도우
# matplotlib의 경우 한글폰트 깨짐현상을 방지하기 위한 코드
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
f_path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family=font_name)
import seaborn as sns
'''
# <우분투용 한글 문제 해결 코드>
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothicCoding')
# Troubleshooting -마이너스가 깨질 경우가 있음. 이 경우 아래 코드 추가
import matplotlib as mpl
mpl.rcParams['axes.unicode_minus']=False
'''
바플롯을 그려보았습니다.
market_count.plot.bar(x='index',y='초대형상권',rot=0)
market_count.plot.bar(x='index',y='대형상권',rot=0)
market_count.plot.bar(x='index',y='중형상권',rot=0)
market_count.plot.bar(x='index',y='중형상권이상의 수',rot=0)
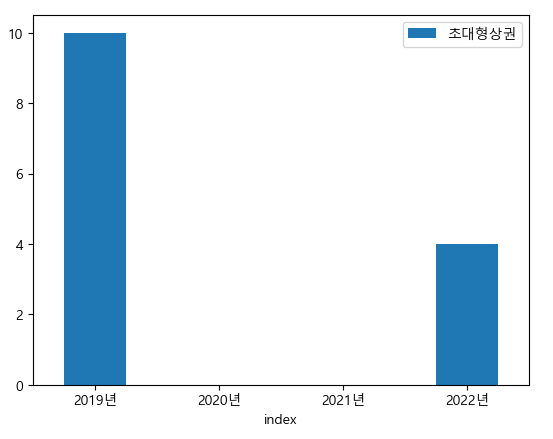
초대형상권은 2019년 10곳에서 2020~2021년까지 없다가 2022년 4곳이 다시 생긴다.
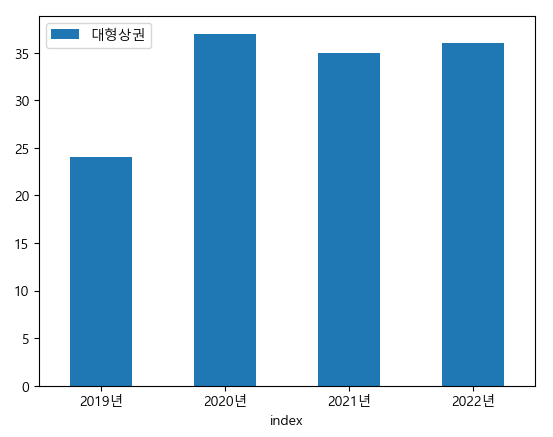
대형상권은 오히려 2020년에 증가했고 2022년에는 2020년에 비해 소폭 감소한다.
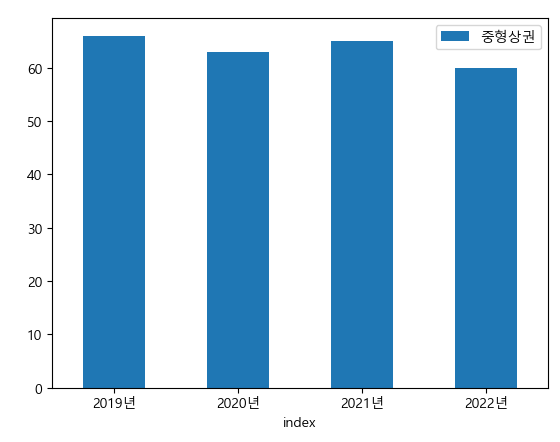
중형상권은 2020년에 한번 많이 사라지는걸 볼 수 있었다.
이번엔 2019년의 초대형상권이 2020년에 대형상권이 되었을까?
my_map_test = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
for each in range(len(most_big_anual_list[0])):
marker_circle = folium.Circle([most_big_anual_list[0]['lat'][each], most_big_anual_list[0]['long'][each]],
radius = 500,
color = 'red',
popup = most_big_anual_list[0]['상권_코드_명'][each],
fill_color = 'red'
)
marker_circle.add_to(my_map_test)
for each in range(len(big_anual_list[1])):
marker_circle = folium.Circle([big_anual_list[1]['lat'][each], big_anual_list[1]['long'][each]],
radius = 500,
color = 'orange',
popup = big_anual_list[1]['상권_코드_명'][each],
fill_color = 'orange'
)
marker_circle.add_to(my_map_test)
my_map_test
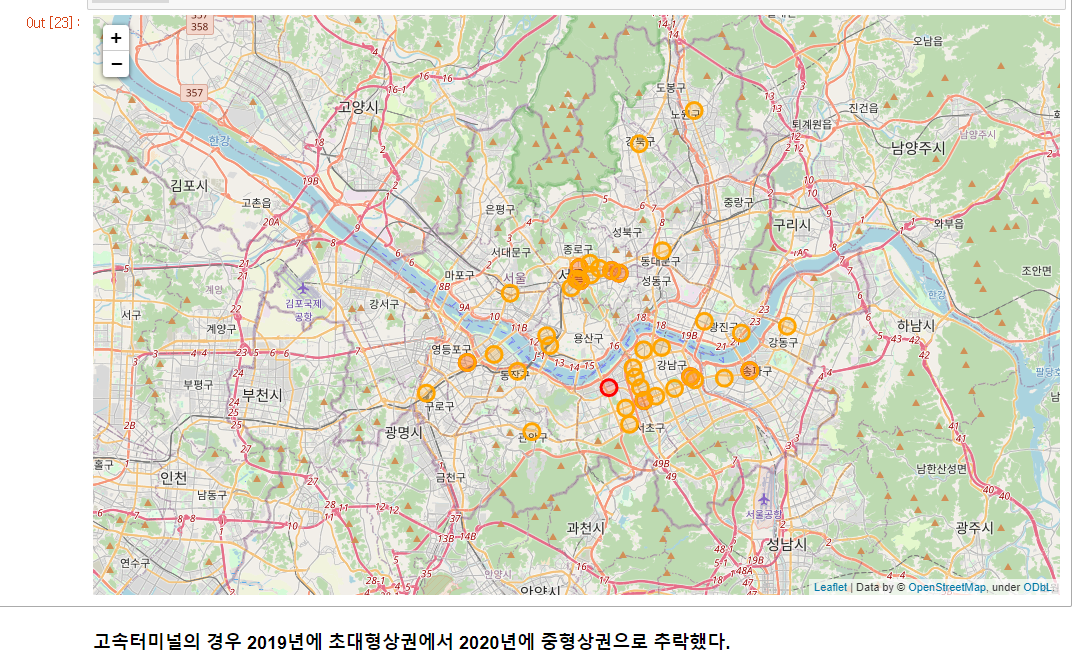
2019년 초대형상권 중 하나인 고터가 2020년에는 중형상권까지 추락한다.
2022년에 초대형 상권 중에 새로생긴곳은?
my_map_test = folium.Map(location=[37.5502, 126.982], zoom_start=12, title="Stamen Toner")
for each in range(len(most_big_anual_list[0])):
marker_circle = folium.Circle([most_big_anual_list[0]['lat'][each], most_big_anual_list[0]['long'][each]],
radius = 500,
color = 'orange',
popup = most_big_anual_list[0]['상권_코드_명'][each],
fill_color = 'orange'
)
marker_circle.add_to(my_map_test)
for each in range(len(most_big_anual_list[3])):
marker_circle = folium.Circle([most_big_anual_list[3]['lat'][each], most_big_anual_list[3]['long'][each]],
radius = 500,
popup = most_big_anual_list[3]['상권_코드_명'][each],
)
marker_circle.add_to(my_map_test)
my_map_test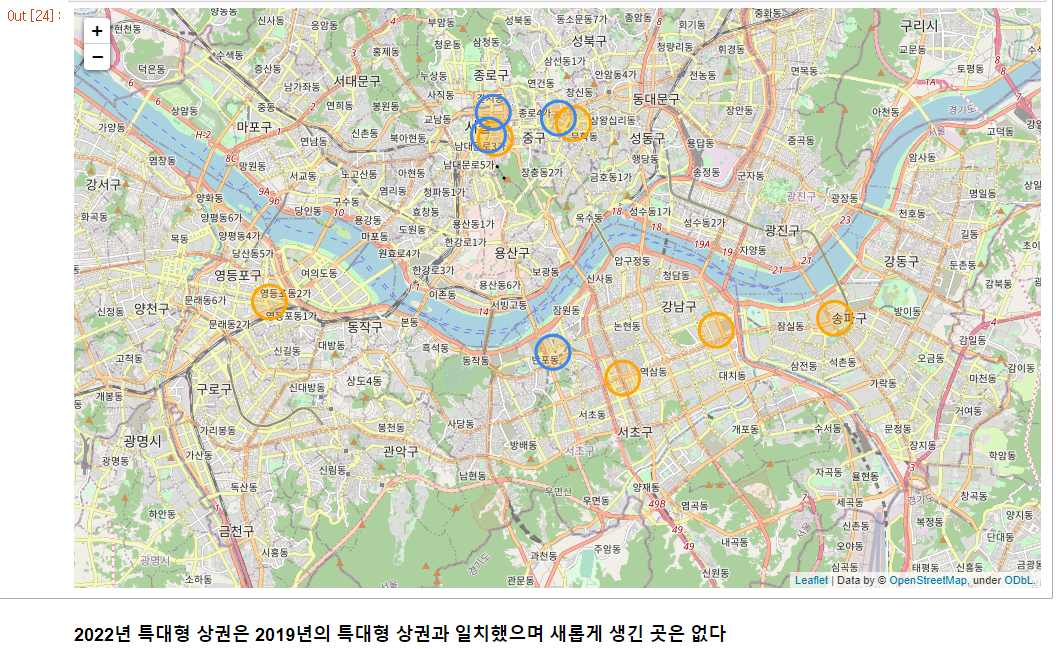
그렇다면 원인은 코로나인가?
market_count = pd.DataFrame({'유동인구' : [market_2019["유동인구"].sum(), market_2020["유동인구"].sum(), market_2021["유동인구"].sum(),
market_2022["유동인구"].sum()],
'중형상권의 수' : [len(market_2019["유동인구"]), len(market_2020["유동인구"]), len(market_2021["유동인구"]),
len(market_2022["유동인구"])],
}, index = ["2019년", "2020년", "2021년", "2022년"])
market_count = market_count.reset_index()
market_count['중형상권 1곳당 유동 인구'] = market_count["유동인구"] / market_count["중형상권의 수"]market_count.plot.bar(x='index',y='중형상권 1곳당 유동 인구',rot=0)
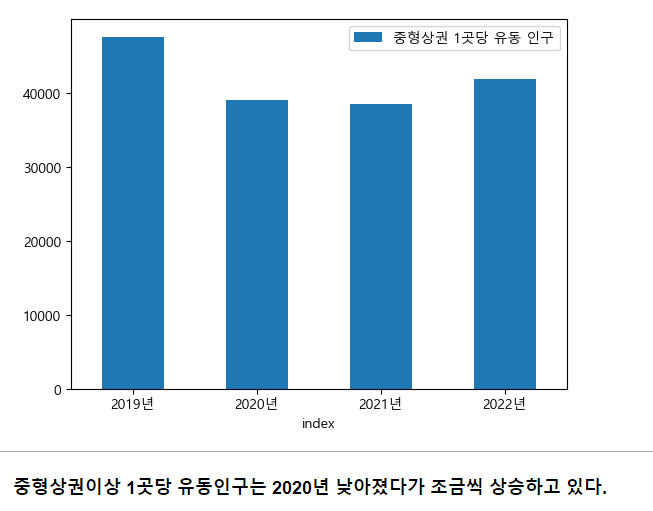
그렇다 2020년 만명정도 유동인구가 감소했으며 그 원인은 코로나가 맞다고 생각한다.
이전 글에서
연도별 서울시 도로별 평균속도를 시각화한 적이 있다.
그 데이터를 가져오자고
그리고 이게 그 평균속도를 시각화해주는 코드
그냥 코드를 깊게 이해하지 말고 이전의 블로그글을 보자.
import numpy as np
from haversine import haversine
from tqdm import tqdm
road_2022 = pd.read_csv('./2022_10_자동차_평균속도_위치데이터.csv', encoding='EUC-KR')
road_2021 = pd.read_csv('./2021_10_자동차_평균속도_위치데이터.csv', encoding='EUC-KR')
road_2020 = pd.read_csv('./2020_10_자동차_평균속도_위치데이터.csv', encoding='EUC-KR')
road_2019 = pd.read_csv('./2019_10_자동차_평균속도_위치데이터.csv', encoding='EUC-KR')
road_list = [road_2019, road_2020, road_2021, road_2022]
for i in range(len(road_list)):
road_list[i] = road_list[i].fillna(0)
road_list[i]["주간평균속도"] = (road_list[i]['출근시간 (06~09)'] + road_list[i]['퇴근시간 (17~20)'] + \
road_list[i]['점심시간(11~13)'] + road_list[i]['오후시간(14~16)']) / 4
road_list[i] = road_list[i][['시점명', '종점명', '방향', '주중,주말', '주간평균속도', '시점 경도', '시점 위도', '종점 경도', '종점 위도']]
road_list[i] = road_list[i][road_list[i]['주중,주말'].isin(["주중"])]
road_list[i] = road_list[i].reset_index()
most_big_anual_list = []
big_anual_list = []
middle_anual_list = []
for i in range(len(market_anual_list)):
most_big_market_region = market_anual_list[i].loc[(market_anual_list[i]['유동인구'] >= 100000)]
most_big_market_region = most_big_market_region.loc[(most_big_market_region['분기당_매출_금액']/91) >= 1000000000]
most_big_market_region["상권규모"] = "특대형상권"
most_big_market_region = most_big_market_region.reset_index()
most_big_anual_list.append(most_big_market_region)
for i in range(len(market_anual_list)):
big_market_region = market_anual_list[i].loc[(market_anual_list[i]['유동인구'] < 100000)]
big_market_region = big_market_region.loc[(big_market_region['분기당_매출_금액']/91) > 1000000000]
big_market_region["상권규모"] = "대형상권"
big_market_region = big_market_region.reset_index()
big_anual_list.append(big_market_region)
for i in range(len(market_anual_list)):
middle_market_region = market_anual_list[i].loc[(market_anual_list[i]['유동인구'] < 100000)]
middle_market_region = middle_market_region.loc[(middle_market_region['분기당_매출_금액']/91) < 1000000000]
middle_market_region["상권규모"] = "중형상권"
middle_market_region = middle_market_region.sort_values(by='유동인구', ascending=False)
middle_market_region = middle_market_region.head(100-len(most_big_anual_list[i])-len(big_anual_list[i]))
middle_market_region = middle_market_region.reset_index()
middle_anual_list.append(middle_market_region)
for i in range(len(market_anual_list)):
most_big_anual_list[i]["상권의 도로 평균 속도"] = 0.
big_anual_list[i]["상권의 도로 평균 속도"] = 0.
middle_anual_list[i]["상권의 도로 평균 속도"] = 0.
def make_road(market_degree, road_data, my_map):
for i in range(len(market_degree)):
road_count = 0
market_region_location = (market_degree['lat'][i], market_degree['long'][i])
for each in range(len(road_data)):
road_location = (road_data['시점 위도'][each], road_data['시점 경도'][each])
a = haversine(road_location, market_region_location, unit = 'm')
if a < 500:
road_count = road_count + 1
market_degree['상권의 도로 평균 속도'][i] = market_degree['상권의 도로 평균 속도'][i] +\
road_data['주간평균속도'][each]
make_poly_line(road_data, each, my_map)
road_location = (road_data['종점 위도'][each], road_data['종점 경도'][each])
a = haversine(road_location, market_region_location, unit = 'm')
if a < 500:
road_count = road_count + 1
market_degree['상권의 도로 평균 속도'][i] = market_degree['상권의 도로 평균 속도'][i] +\
road_data['주간평균속도'][each]
make_poly_line(road_data, each, my_map)
market_degree["상권의 도로 평균 속도"][i] = market_degree['상권의 도로 평균 속도'][i] / road_count
그래서 맵을 4개 만들고
my_map_road_2019 = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
my_map_road_2020 = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
my_map_road_2021 = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
my_map_road_2022 = folium.Map(location=[37.5502, 126.982], zoom_start=11, title="Stamen Toner")
map_road_list = [my_map_road_2019, my_map_road_2020, my_map_road_2021, my_map_road_2022]
for i in range(4):
gu_line(map_road_list[i])
make_road(most_big_anual_list[i], road_list[i], map_road_list[i])
make_road(big_anual_list[i], road_list[i], map_road_list[i])
make_road(middle_anual_list[i], road_list[i], map_road_list[i])
make_market_region(most_big_anual_list[i], big_anual_list[i], middle_anual_list[i], map_road_list[i])
그래서 우리는 이제 상권을 지나는 도로의 평균속도를 구할려고 한다.
그 전에 재미로 상권을 지나는 도로만 시각화를 한 번 해보려고 한다.
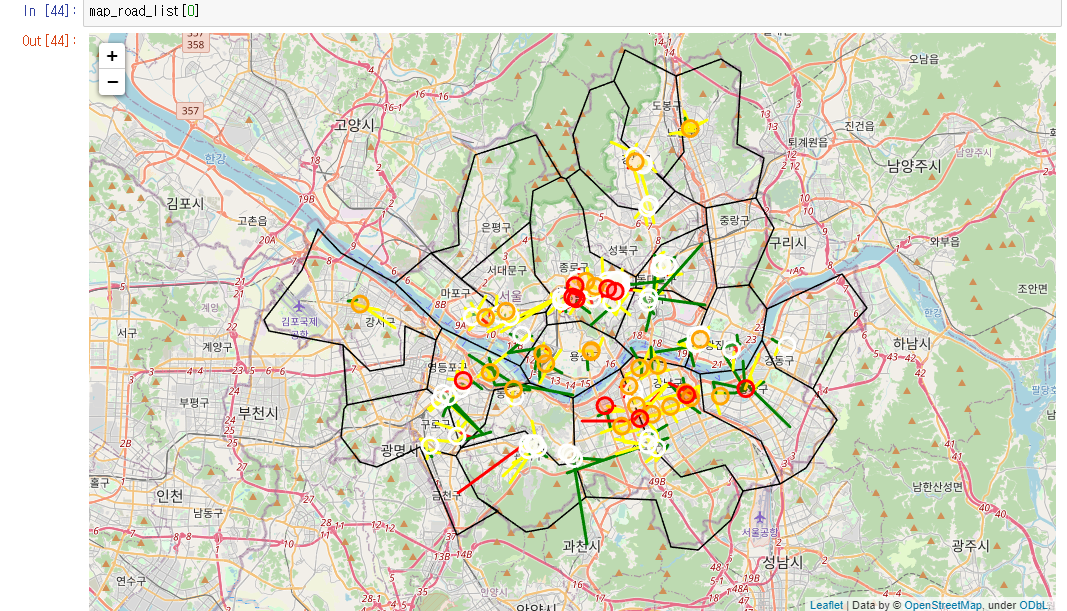
2019년
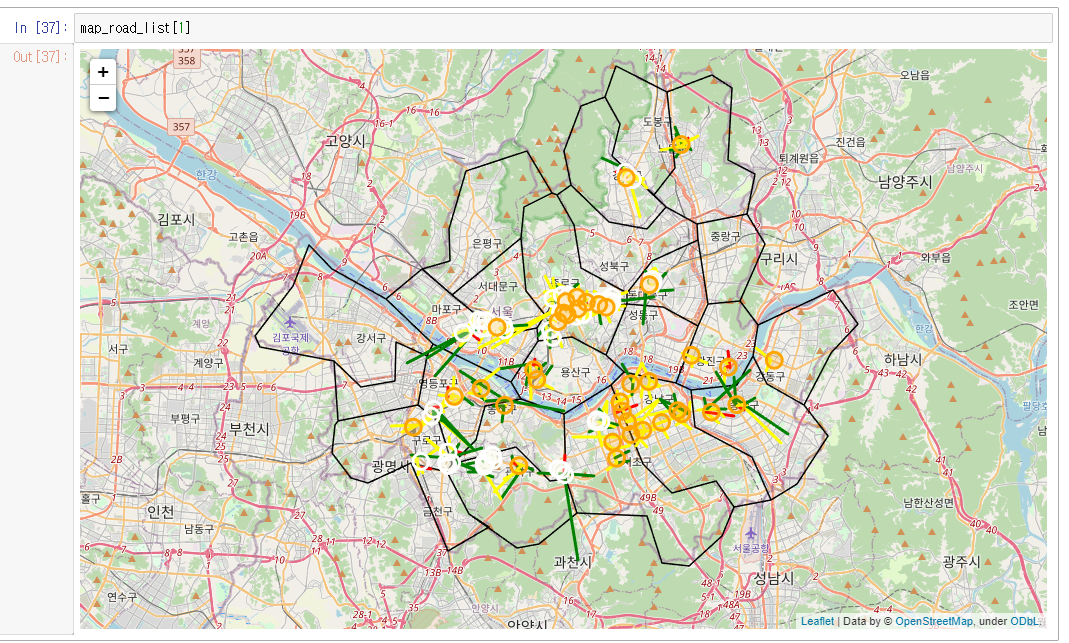
2020년
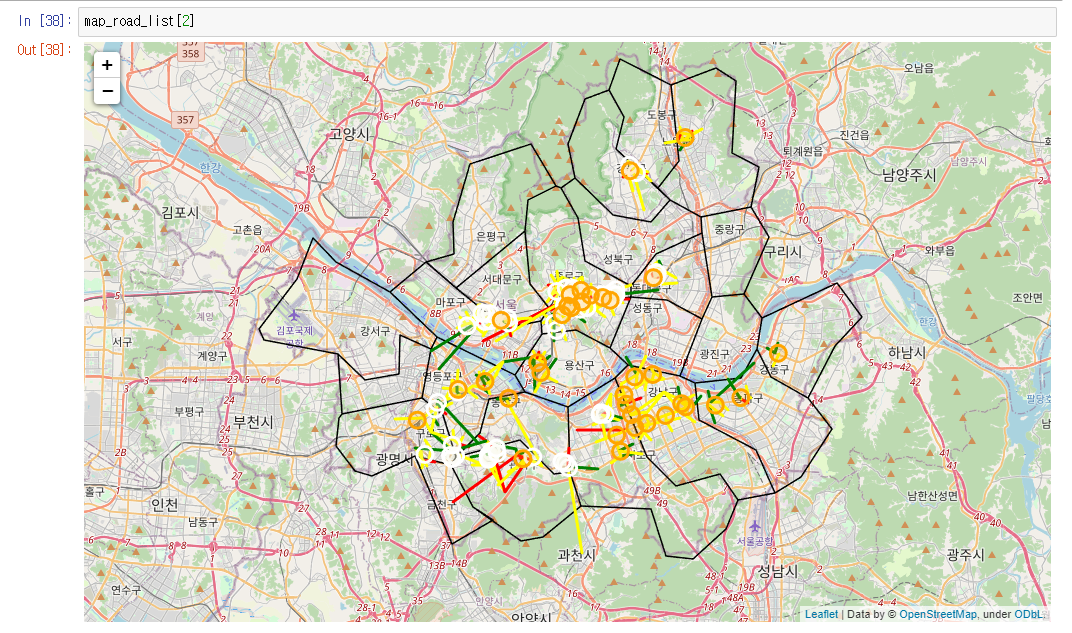
2021년
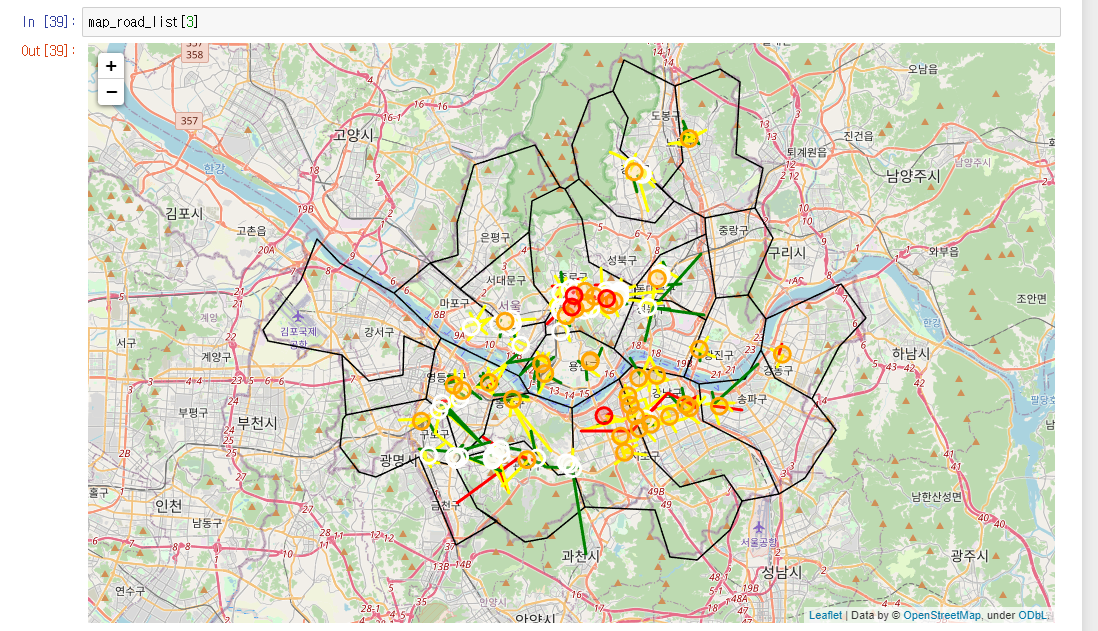
2022년
지도만 보고서는 모르겠으니까
종로구를 확대시켜보자고
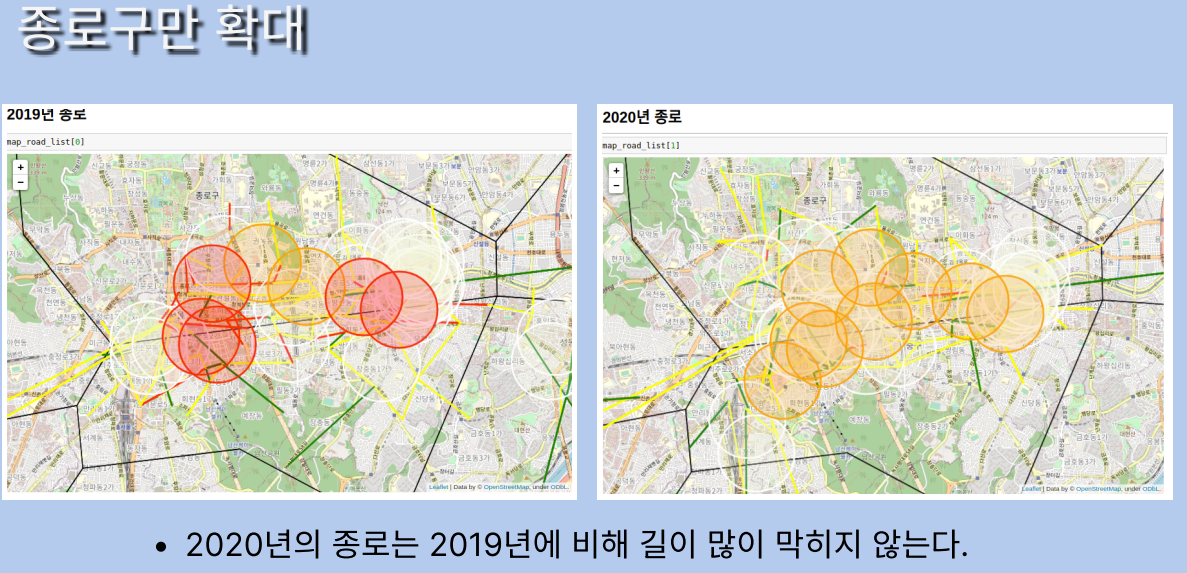
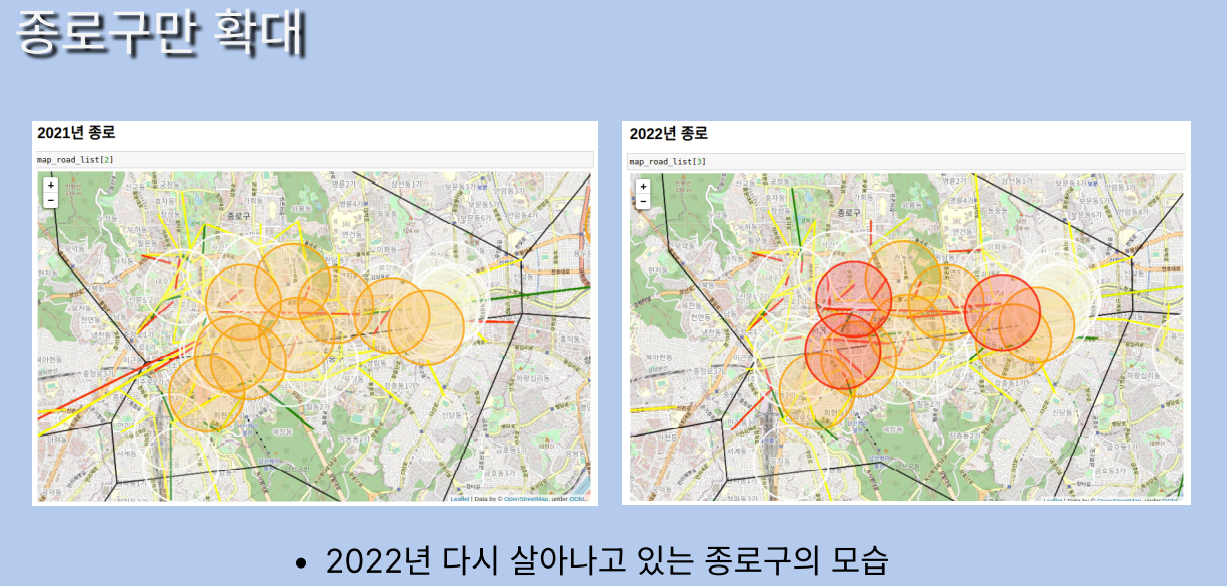
이제 수치적으로 한 번 봅시다.
year_list = [2019, 2020, 2021, 2022]
for i in range(4):
most_big_anual_list[i]["연도"] = year_list[i]
big_anual_list[i]["연도"] = year_list[i]
middle_anual_list[i]["연도"] = year_list[i]
most_big_traffic = pd.concat([most_big_anual_list[0],
most_big_anual_list[1],
most_big_anual_list[2],
most_big_anual_list[3]])
big_traffic = pd.concat([big_anual_list[0],
big_anual_list[1],
big_anual_list[2],
big_anual_list[3]])
middle_traffic = pd.concat([middle_anual_list[0],
middle_anual_list[1],
middle_anual_list[2],
middle_anual_list[3]])
most_big_traffic.to_csv('./특대형상권 2019~2022년 통계.csv', index=False)
big_traffic.to_csv('./대형상권 2019~2022년 통계.csv', index=False)
middle_traffic.to_csv('./중형상권 2019~2022년 통계.csv', index=False)big = pd.read_csv('./대형상권 2019~2022년 통계.csv')
very_big = pd.read_csv('./특대형상권 2019~2022년 통계.csv')
middle = pd.read_csv('./중형상권 2019~2022년 통계.csv')
대충 이런건 넘어가고 결과를 빨리 보여주고싶어요
# <한글 문제 해결 코드>
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothicCoding')
# Troubleshooting -마이너스가 깨질 경우가 있음. 이 경우 아래 코드 추가
import matplotlib as mpl
mpl.rcParams['axes.unicode_minus']=Falsebig = big[['상권_코드_명','상권규모', '연도', '유동인구', '분기당_매출_건수', '분기당_매출_금액', '환승가능한버스노선', '500m 버스정류장', '환승가능지하철', '환승가능 호선명', '500m 지하철역', '상권의 도로 평균 속도']]
very_big = very_big[['상권_코드_명','상권규모', '연도', '유동인구', '분기당_매출_건수', '분기당_매출_금액', '환승가능한버스노선', '500m 버스정류장', '환승가능지하철', '환승가능 호선명', '500m 지하철역', '상권의 도로 평균 속도']]
middle = middle[['상권_코드_명','상권규모', '연도', '유동인구', '분기당_매출_건수', '분기당_매출_금액', '환승가능한버스노선', '500m 버스정류장', '환승가능지하철', '환승가능 호선명', '500m 지하철역', '상권의 도로 평균 속도']]
big
df= pd.concat([very_big, big, middle])
df.loc[df['상권규모'] == "특대형상권", '상권규모'] = "초대형상권"
df.head(30)
대충 이런건 넘어가고 결과를 빨리 보여주고싶어요
결과가 이상해서 한 번 뽑아보았습니다.
분기당 매출을 상권의 규모별로 비교해봅시다.
sns.catplot(x="연도", y='분기당_매출_금액', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)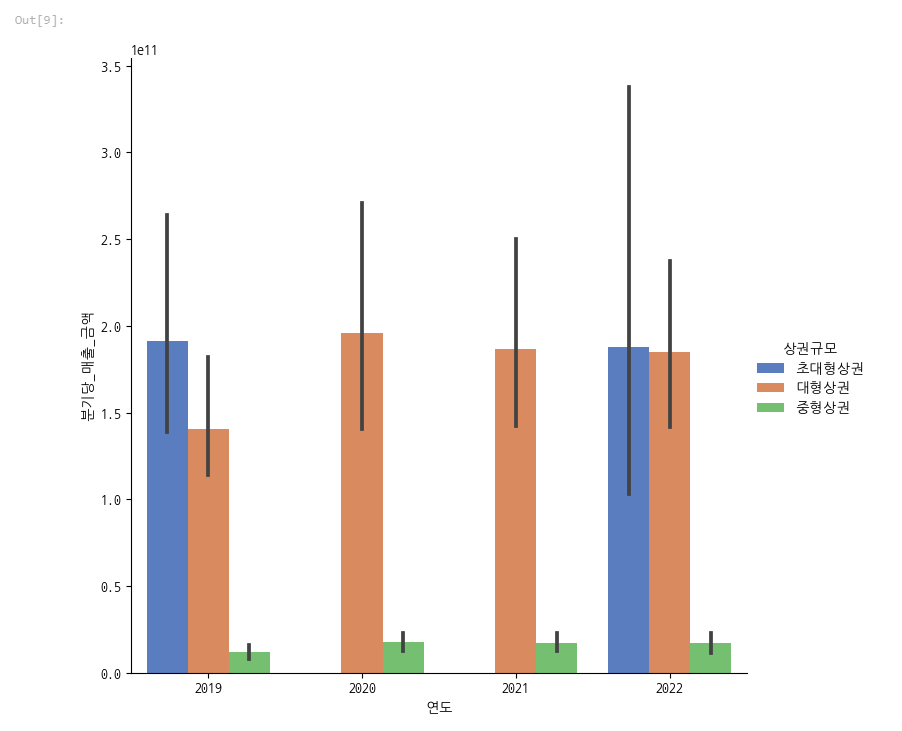
초대형상권이랑 대형상권이 압도적으로 높습니다.
sns.catplot(x="연도", y='분기당_매출_건수', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)
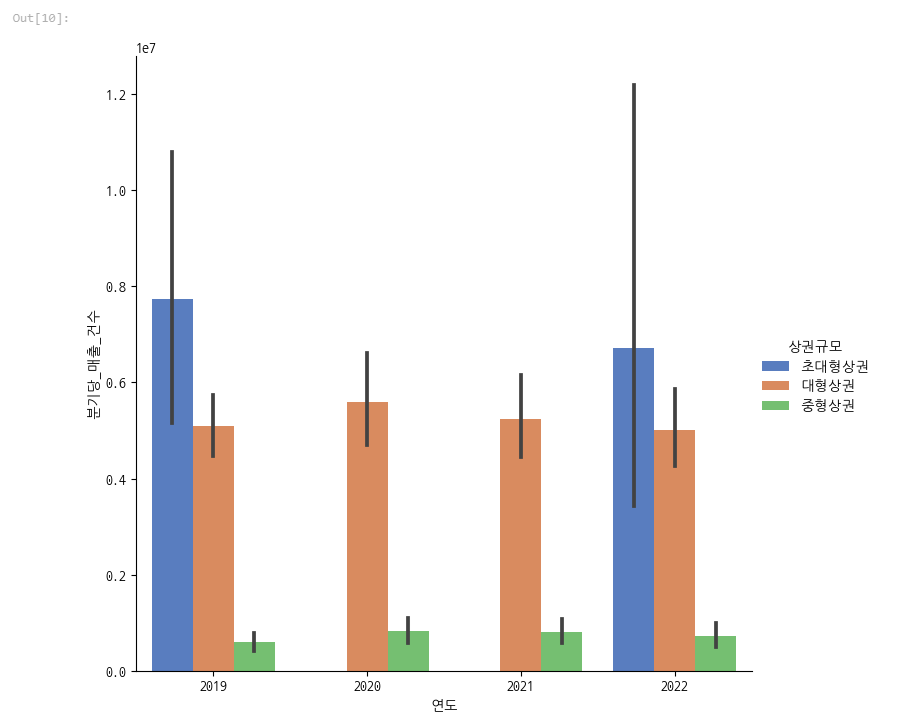
매출건수도 마찬가지였죠
그러면 버스를 한 번 비교해봅시다.
sns.catplot(x="연도", y='환승가능한버스노선', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)
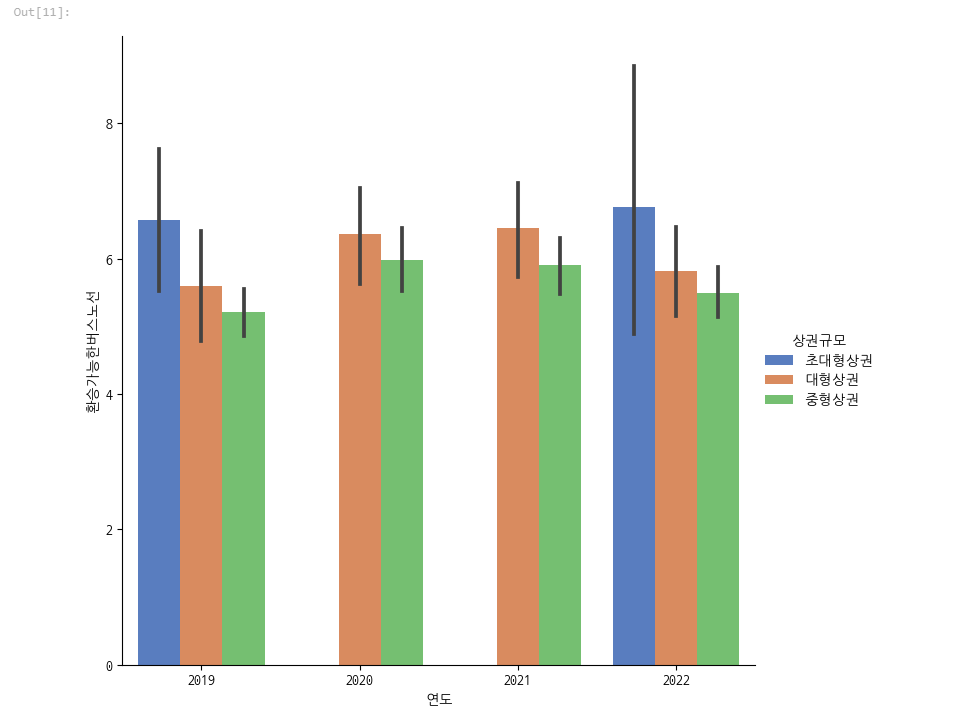
초대형상권의 경우 버스노선이 다른 상권보다 많았습니다.
대형상권도 많았구요
sns.catplot(x="연도", y='500m 버스정류장', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)
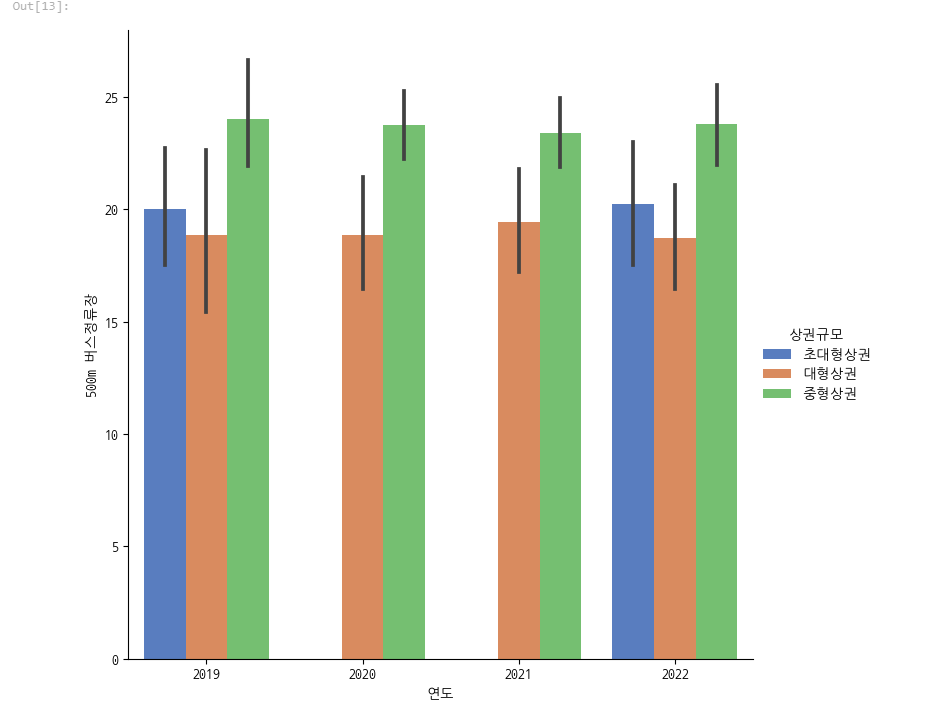
그런데 버스정류장은 중형상권이 더많았습니다.
지하철역 같은 경우에는
sns.catplot(x="연도", y='500m 지하철역', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)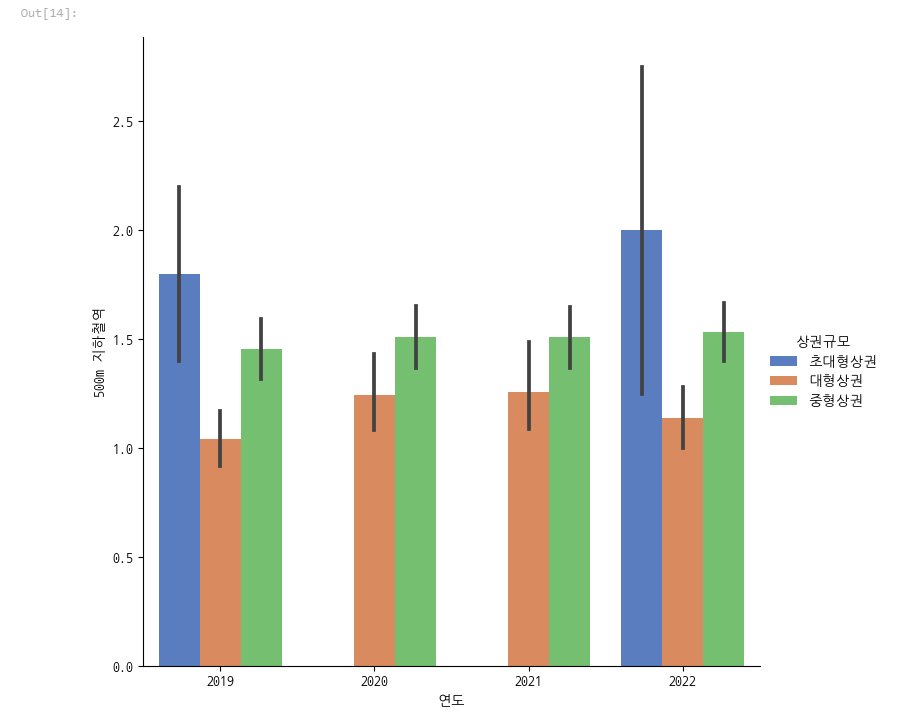
초대형이 많은건 이해가 되지만 오히려 중형상권이 더 많았습니다.
환승가능한 지하철역의 경우에도
중형상권이 많았습니다.
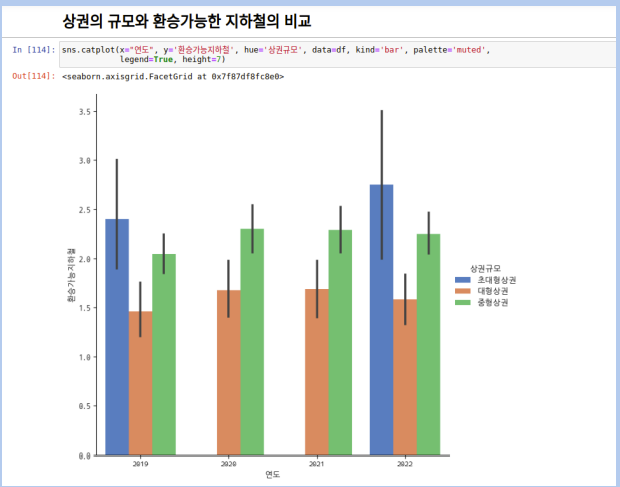
도로의 평균속도의 경우에도
sns.catplot(x="연도", y='상권의 도로 평균 속도', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)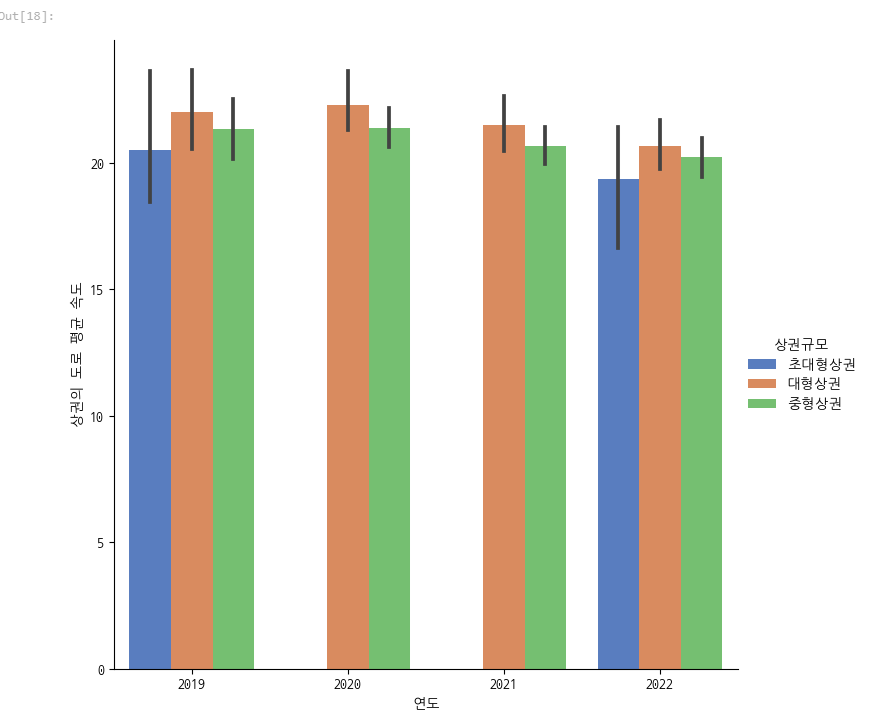
중형상권이 속도가 더 낮았습니다. 이는 유동인구가 중형상권이 더 많기 때문일까요?
sns.catplot(x="연도", y='유동인구', hue='상권규모', data=df, kind='bar', palette='muted',
legend=True, height=7)
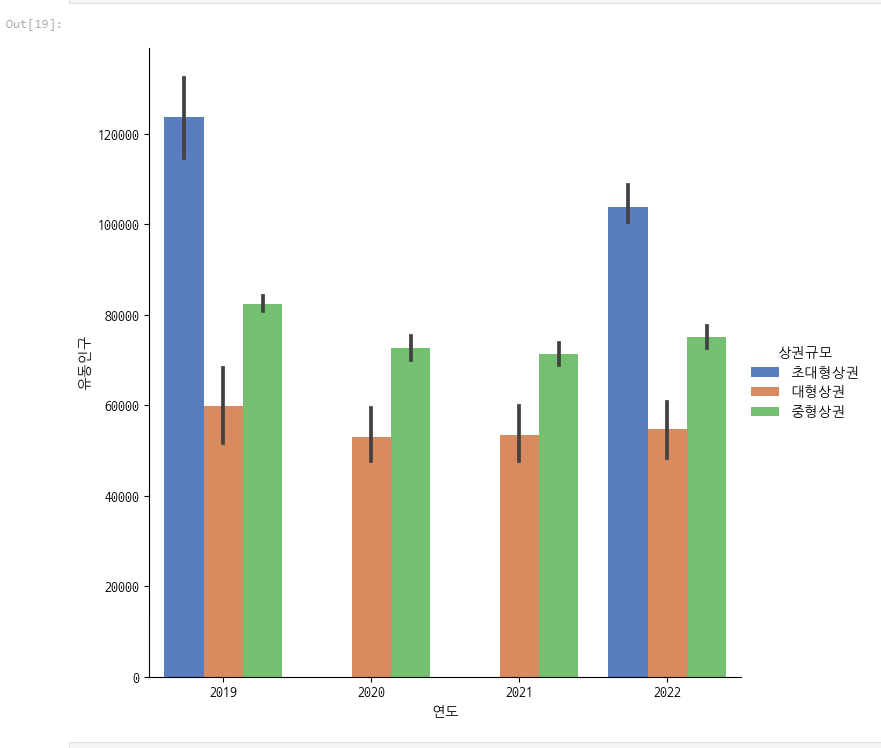
그렇습니다. 초대형상권의 경우 유동인구가 압도적으로 많지만
중형상권의 경우가 대형상권보다 유동인구가 많았습니다.
그런데 매출은 대형상권이 더 높다니 의외의 결과였습니다.
그래서 결론적으로 초대형상권의 경우 교통인프라가 많지만
대형상권의 경우 중형상권보다 교통인프라가 부족하다고 느껴집니다.
그리고 최근 유동인구가 증가하고 있는 추세에서
안타까운 사고도 발생했고
서울시는 군중밀집을 해소하기 위해 철저한 안전대책 수립이 필요하다고 생각됩니다.
'ㅇ 프로젝트 > TEAM_서울시 교통 인프라 분석' 카테고리의 다른 글
| 12. 프로젝트를 마치며 (0) | 2022.11.20 |
|---|---|
| (팀원) 11. 서울시 주차장을 분석해보자. (0) | 2022.11.20 |
| (팀원) 9. 서울시 도로율 분석 및 시각화 (0) | 2022.11.20 |
| (팀원) 8. 서울시와 뉴욕시의 교통사고 데이터 분석 및 시각화 (0) | 2022.11.20 |
| 7. 서울시 상권데이터를 분석하자. (0) | 2022.11.19 |