참고도서 : 파이썬 알고리즘 인터뷰 . 박상길 . 책만 . 2020
참고도서에서 언급하는 알고리즘 주제를 참고하여 C++로 풀어보는 것을 목표로 합니다.
알고리즘을 공부하면서도 소프트웨어적 설계를 추가합니다. 답을 내는 코드를 짜는게 아니라 각각이 모듈이 되어 서로 맞물려 동작하는 코드를 짜는 것을 목표로합니다. (그래서 다른 글보다 코드가 깁니다.)
참고로 상위 레벨의 코드를 볼 수록
using namespace std; 라는 코드가 보이지 않아, 없이 진행합니다.
1371번: 가장 많은 글자
첫째 줄부터 글의 문장이 주어진다. 글은 최대 50개의 줄로 이루어져 있고, 각 줄은 최대 50개의 글자로 이루어져 있다. 각 줄에는 공백과 알파벳 소문자만 있다. 문장에 알파벳은 적어도 하나 이
www.acmicpc.net


가장 많이 등장한 알파벳은 무엇인가요?
풀이를 시작해봅시다.
결국 가장 쉬운 방법으로는 a부터 z까지 선언하고나서 포문을 돌면서 맞는거 끼워넣으면 되는거 아닌가?
근데, 그렇게하면 메모리 효율성면에서 좋지 못한 선택이 될 것이라 생각하지만 일단 만들어보자.
1. 알파벳의 개수만큼의 벡터를 선언한다.
3. 알파벳 - 'a' 하면 결국 벡터의 인덱스가 나온다. 그 인덱스에 1을 더한다.
4. MAX 값을 뽑는다.
그러면 메인문에서는 벡터를 선언한다.
문장과 벡터를 보내면 이를 참조해서 올리는 함수를 하나 만든다. 이름은 count alphabet 으로하자.
일단 뼈대부터 만들어보자.
#include <iostream>
#include <vector>
void count_Alphabet(const std::string &sentence, std::vector<int> &alphabet) {
}
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence; std::cin >> sentence;
count_Alphabet(sentence, alphabet);
}
여기서 C++ 문법의 팁이 하나 있다면
std::vector<int> alphabet(26, 0);이 부분이라고 볼 수 있을 것 같습니다. 26개 모두 0으로 초기화해주세요.
우리는 일단 단계적으로 구현을 해야하는 상황입니다. 어떻게 알파벳을 count 시킬건가요?
조건문을 26번 써야하나요? 아닙니다.
vector[0] = 0 일때 vector[0]은 어떤 알파벳을 count 하고 있을까요? a 입니다.
그러면 'a' - 'a' = 0 입니다. 그러니 우리는 조건문을 26번 작성할 필요없습니다.
'b' - 'a' = 1 인 것처럼 조건문을 한 번만 사용해도 충분합니다.
그러면 다음처럼 코드가 짜여질 것입니다.
void count_Alphabet(const std::string &sentence, std::vector<int> &alphabet) {
for (auto & i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}그러면 여기까지 진행하면 count_Alphabet 함수는 끝입니다.
우선은 count 된 알파벳을 출력하는 형태로 단계를 분할해서 잘 되는지 확인을 해봅시다.
#include <iostream>
#include <vector>
void count_Alphabet(const std::string &sentence, std::vector<int> &alphabet) {
for (auto & i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence; std::cin >> sentence;
count_Alphabet(sentence, alphabet);
char print_alphabet = 'a';
for (auto& i : alphabet) {
std::cout << print_alphabet << " : " << i << " " << std::endl;
print_alphabet++;
}
}가장 쉬운걸 하나 넣읍시다
aaabbbcccdddeeeffzzz
이거를 넣어보죠

그러면 일단 목표대로 돌아가기 때문에 출력하는 부분을 지우고 다음 단계로 넘어갑시다.
자 다시 이상태입니다.
#include <iostream>
#include <vector>
void count_Alphabet(const std::string &sentence, std::vector<int> &alphabet) {
for (auto & i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence; std::cin >> sentence;
count_Alphabet(sentence, alphabet);
}
그러면 vector에 Max라는 함수가 있을까요?
파이썬에서는 그냥 np.max() 해버리면 끝납니다. 근데, C++ 은 조금 상황이 다릅니다.
이 참에 한 가지를 연구해서 아예 암기해버립시다.
큰 수를 찾는 방법은 보통
for문을 돌면서 int max = 0 을 하나 선언합니다.
vector를 돌면서 큰 수가 나오면 그 수를 max값으로 바꿉니다.
그러면 마지막에 max값을 찾을 수 있습니다.
그러나 문제는 보통 해당 방법으로 짜여진 함수들은 하나의 값만 반환합니다.
문제에서 원하는 것처럼 여러 개의 인덱스가 필요하다는 경우를 맞출 수가 없습니다.
참고삼아서 vector에서 최대값을 찾는 함수를 밑에 놓았습니다.
방금 언급한대로 여러 개의 인덱스가 필요한 상황이기 때문에 우리는 이걸 만들어야합니다.
#include<algorithm>
int max = *max_element(v.begin(), v.end());
// 가장 큰 수가 리턴
int max_index = max_element(v.begin(), v.end())-v.begin();
// 가장 큰 수의 인덱스가 리턴
int min = *min_element(v.begin(), v.end());
// 가장 작은 수가 리턴
int min_index = min_element(v.begin(), v.end())-v.begin();
// 가장 작은 수의 인덱스가 리턴
그러니 함수를 하나 새로 만듭시다. 이름은 my_max_element 로 하겠습니다.
반환값은 인덱스 값을 가지고 있는 vector가 될 것입니다.
왜 answer가 vector 형식인가요?
-> a가 3개 b가 3개면 ab를 출력해야합니다.
우선 vector를 반환하는 경우에 메모리 효율상으로 어떻게 접근해야할지 몰라 우선은 짜고 나서 chatgpt를 통해서 이 방법에서 가장 메모리 효율을 생각한 방법이 뭐야? 물어보도록 하겠습니다.
그리고 const 형태로 alphabet count vector를 참조값으로 받아와야합니다. const인 이유는 위 변수는 절대변경되면 실수라도 변경되는 경우를 막기 위함입니다.
그래서 결론적으로 다음처럼 함수를 하나 새로 만들었습니다.
std::vector<int> my_max_element(const std::vector<int>& alphabet) {
}
// 혹시나 반환값 저게 아닌데? 싶으시면 일단 이해를 해주시기 바랍니다. 저도 몰라서 이렇게 적고
// 뒤에서 이렇게 하는게 맞더라 언급하겠습니다.
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence; std::cin >> sentence;
count_Alphabet(sentence, alphabet);
std::vector<int> answer = my_max_element(alphabet);
}
// 그럼 메인문은 저렇게 될 것 입니다.그러면 함수를 한 번 완성시켜보도록 하겠습니다.
우선 int max를 하나 선언합니다 이 값은 1입니다.
(1인 이유는 뒤를 생각해보면 이해될 것이라 생각합니다.)
그러면 전체 vector를 돌면서 1이랑 같은 값이 나타나면
vector에 index를 push_back합니다. 그러나 1보다 큰 값이 나타나면?
vector를 초기화하고 다시 push_back 해야합니다.
만약 int max = 0 이였다면 0이 많은 상황에서 계속 vector에 추가를 하게되었겠죠?
코드를 보시겠습니다.
std::vector<int> my_max_element(const std::vector<int>& alphabet) {
int max = 1;
std::vector<int> index_list;
for (int i=0; i<alphabet.size(); i++){
if (alphabet[i] == max)
index_list.push_back(i);
else if (alphabet[i] > max) {
index_list.clear();
index_list.push_back(i);
max = alphabet[i];
}
}
return index_list;
}살짝 복잡할 수도 있으니까 설명을 하자면
여기서는 for (auto &i : alphabet)을 쓰기는 어렵습니다.
왜냐면 index의 값이 필요한데 쓸데없이 변수를 하나 더 생성을 해야하니까요
그래서 만약에 max와 같다면 list에 추가를 해주시고
크다면 vector를 초기화 하고, 지금의 i값을 넣어주세요.
그 다음에 max를 alphabet[i]으로 바꿔주셔야 하겠죠?
그러면 잘 작동하는지 테스트를 해보겠습니다.
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence; std::cin >> sentence;
count_Alphabet(sentence, alphabet);
std::vector<int> answer = my_max_element(alphabet);
for (auto& i : answer) {
std::cout << i;
}
}main을 다음으로 수정하고 돌려보겠습니다.
aaabbcdddeffzzz
를 돌려보겠습니다. 예상 출력값은 adz 입니다.
그리고 sort를 해야할까 고민하실 수도 있는데, push_back 하는 순서가 이미 a~z순이기 때문에 필요없습니다.

한가지 예상을 잘못했네요. 다음처럼 수정합니다.
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence; std::cin >> sentence;
count_Alphabet(sentence, alphabet);
std::vector<int> answer = my_max_element(alphabet);
for (auto& i : answer) {
std::cout << (char)(i+'a');
}
}
이제 될겁니다.

정상적으로 출력해줍니다.
아까 궁금했었던 반환값이 적절한가? 에 대한 질문을 chatgpt에게 하고 오겠습니다.
my_max_element 함수의 반환값으로 std::vector<int>을 사용하는 것은
최대값을 가지는 요소의 인덱스를 모두 저장할 수 있는 장점이 있습니다.
따라서, 여러 개의 인덱스를 반환해야 하는 경우에는 std::vector<int>를 사용하는 것이 적절합니다.
alphabet 매개변수는 const 참조로 전달되기 때문에,
alphabet 벡터 자체를 반환해도 메모리 복사가 발생하지 않으므로 큰 문제는 없습니다.
하지만 alphabet 벡터가 매우 큰 경우에는 반환값으로
std::vector<int> 대신 std::vector<size_t>를 사용하여 인덱스만을 저장하는 것이 더 효율적일 수 있습니다.
따라서, my_max_element 함수의 반환값으로 std::vector<int>을 사용해도 큰 문제는 없지만,
반환값의 크기가 매우 큰 경우에는 std::vector<size_t>를
사용하여 반환값의 메모리 사용량을 줄이는 것이 좋습니다.
chat gpt 말로는 std::vector<int>를 반환해도 좋다고 합니다. 그러나 인덱스만을 저장하는 size_t라는 방법이 있다고 합니다. 이것에 대한 질문도 해보겠습니다.
그러면 제가 드린 코드의 반환값을 std::vector<size_t>로 만들어서 주시고, size_t가 도대체 어떤 놈이며, 어떤상황에서 활용하는지 알려주십쇼
std::vector<size_t> my_max_element(const std::vector<int>& alphabet) {
size_t max = 1;
std::vector<size_t> index_list;
for (size_t i=0; i<alphabet.size(); i++){
if (alphabet[i] == max)
index_list.push_back(i);
else if (alphabet[i] > max) {
index_list.clear();
index_list.push_back(i);
max = alphabet[i];
}
}
return index_list;
}다음처럼 변경이 가능하며 chatgpt는 다음처럼 언급합니다.
size_t는 부호 없는 정수형 타입으로, 컴파일러와 CPU 아키텍처에 따라 크기가 다를 수 있지만,
대개 32비트 시스템에서는 4바이트, 64비트 시스템에서는 8바이트 크기를 가집니다.
size_t는 주로 배열의 인덱스, 메모리 블록의 크기, 포인터 산술 등에 사용됩니다.
std::vector<size_t>를 사용하는 경우는 주로 인덱스 값을 저장해야 하는 경우입니다.
예를 들어, 특정 문자열에서 문자의 위치를 찾는 경우, 문자열의 길이가 매우 크고,
문자 위치를 모두 저장해야 하는 경우 std::vector<size_t>를 사용하여
인덱스 값을 저장하는 것이 메모리 효율적입니다.
또한, std::vector<size_t>는 정수형 타입이므로 std::vector<int>와 달리 인덱스 값만을 저장하기 때문에
벡터에 저장된 값의 크기가 std::vector<int>보다 작습니다. 이러한 이유로,
인덱스 값을 저장해야 하는 경우에는 std::vector<size_t>을 사용하는 것이 좋습니다.즉 int로 인덱스를 저장하면 바이트가 너무 커서 size_t로 메모리를 효율적으로 잡게 하라는 것으로 보입니다. 이 부분은 벡준에 제출을 하면서 비교분석 하도록 하겠습니다.
제출을 해보겠습니다.
제출을 하고 보니 입력을 받을 때 문제가 있다는 것을 알게되었습니다. 바로 다음과 같은 경우입니다.
english is a west germanic
language originating in england
and is the first language for
most people in the united
kingdom the united states
canada australia new zealand
ireland and the anglophone
caribbean it is used
extensively as a second
language and as an official
language throughout the world
especially in common wealth
countries and in many
international organizations이런식으로 입력을 해버리면? 문제가 발생합니다. 그래서 우리는 문자열에 대해서 이해를 해야합니다.
getline은 \n 즉 개행문자로 이를 구분합니다.
그런데 \n 으로 계속 입력을 받으면 \n이 올때까지 계속 기다립니다. 그렇기 때문에 우리는 EOF라는 것을 알아야합니다.
EOF까지만 입력을 받으면 됩니다. 그렇게 수정을 하겠습니다.
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence = "";
std::string line;
int t = 0;
while(t < 50 || !std::cin.eof()){
getline(std::cin, line);
sentence += line;
t++;
}
count_Alphabet(sentence, alphabet);
std::vector<size_t> answer = my_max_element(alphabet);
for (auto& i : answer) {
std::cout << (char)(i+'a');
}
}50줄을 넘어가거나 cin.eof 에 도달하는 경우 입력을 중지합니다. 터미널상에서는 유저가 직접 eof 컨트롤 z를 인가하지만 문제에서는 직접 풀어준다는 것 같습니다.
망할 입력..

전체 코드입니다.
#include <iostream>
#include <vector>
#include<algorithm>
#include<string>
void count_Alphabet(const std::string &sentence, std::vector<int> &alphabet) {
for (auto & i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}
std::vector<size_t> my_max_element(const std::vector<int>& alphabet) {
size_t max = 1;
std::vector<size_t> index_list;
for (size_t i = 0; i < alphabet.size(); i++) {
if (alphabet[i] == max)
index_list.push_back(i);
else if (alphabet[i] > max) {
index_list.clear();
index_list.push_back(i);
max = alphabet[i];
}
}
return index_list;
}
int main() {
std::vector<int> alphabet(26, 0);
std::string sentence = "";
std::string line;
int t = 0;
while(t < 50 || !std::cin.eof()){
getline(std::cin, line);
sentence += line;
t++;
}
count_Alphabet(sentence, alphabet);
std::vector<size_t> answer = my_max_element(alphabet);
for (auto& i : answer) {
std::cout << (char)(i+'a');
}
}
언제나 그렇듯 다른 사람의 코드를 점검하는 시간을 가집시다.
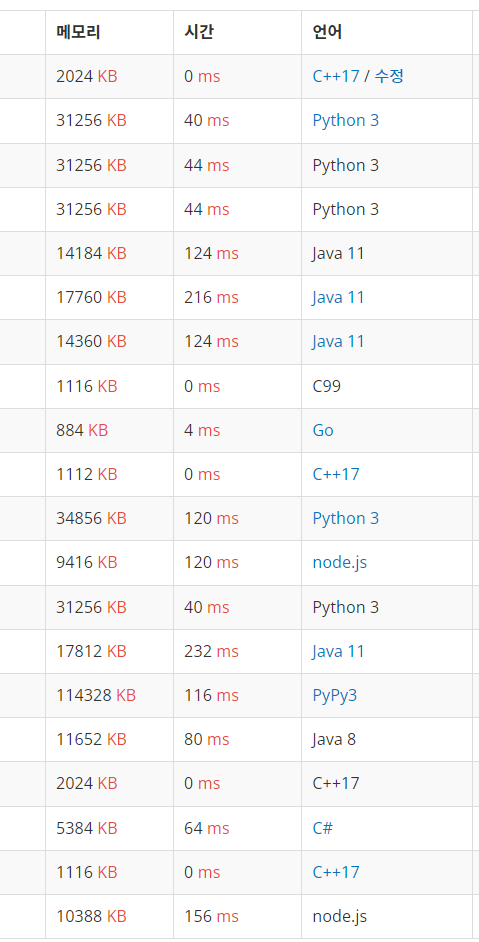
진짜 C언어의 장점을 볼 수 있는 문제인 것 같습니다. 다른 언어로 풀이가된것은 모두 0ms는 절대 나올 수가 없는 것 같습니다.
왜 파이썬은 느릴까요?

어떻게 보면 파이썬의 장점일 수도 있습니다. 다음은 niceotter 님의 코드입니다.
import sys
r=sys.stdin.read()
d={}
for i in range(26):
s=chr(97+i)
c=r.count(s)
if c not in d: d[c]=''
d[c]+=s
print(d[max(d)])코드를 엄청나게 간략화 시킬 수 있으면서, 주어진 라이브러리를 잘 활용하면
파이썬으로는 정말 손쉽게 코딩이 가능합니다. 그러나 파이썬을 배웠는데도 위의 코드는 해석이 어렵네요.
count라는 함수가 아마 알파벳의 개수를 count하는 함수일 것입니다.
다음은 starbow님의 코드입니다.
#include <iostream>
#include <algorithm>
#include <string>
#include <vector>
#include <stack>
#include <queue>
#include <deque>
#include <cmath>
using namespace std;
typedef long long ll;
typedef pair<int, int> ii;
typedef pair<double, double> dd;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL); cout.tie(NULL);
int cnt[26] = {0, };
string s;
while(getline(cin, s)) {
for(auto &c: s) {
if('a' <= c && c <= 'z') cnt[c-'a']++;
}
}
int maxV = 0;
for(int i = 0; i < 26; i++) maxV = max(maxV, cnt[i]);
for(int i = 0; i < 26; i++) {
if(cnt[i] == maxV) cout << (char)('a'+i);
}
return 0;
}일단 vector를 사용하지 않고 int 배열로 26개를 선언했습니다. 여기까지는 저와 같습니다.
그리고 거기서 읽어들이자마자. 알파벳을 판별하여 int 배열을 count 했습니다.
알파벳을 돌면서 max함수를 이용해서 maxV를 구합니다.
아.. max함수는 하나의 값밖에 없습니다.
vector로 함수로 서로 주고 받을 필요없이 그냥 max값과 같으면 출력시켜로 하면 끝납니다. 이런 접근 방법을 몰랐군요.
여튼 이번 글에서 가장 중요하게 배운 것은 공백을 포함하고 개행문자를 포함한 입력은 어떻게 받는가? 였던것 같습니다.
while(t < 50 || !std::cin.eof()){
getline(std::cin, line);
sentence += line;
t++;
}다음의 방법이 될 수도 있고
while(true){
string inp;
cin >> inp;
if(cin.eof())
break;다음의 방법이 될 수도 있는 것 같습니다.
유사 고난도 문제
코딩테스트 연습 - [3차] 압축 | 프로그래머스 스쿨 (programmers.co.kr)
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
Most Common Word - LeetCode
Can you solve this real interview question? Most Common Word - Given a string paragraph and a string array of the banned words banned, return the most frequent word that is not banned. It is guaranteed there is at least one word that is not banned, and tha
leetcode.com
다음의 문제입니다만 현재 시간관계상 넘어가겠습니다.
유사 백준문제를 찾을 수가 없네요.
'ㅇ 공부#언어 > (C++) 알고리즘' 카테고리의 다른 글
| (C++)알고리즘 탐구 5. 브루트 포스 (1/2) (풀이, 알고리즘 분석) (1) | 2023.04.05 |
|---|---|
| C++ 코딩 테스트 기술 모음 (0) | 2023.04.03 |
| (C++)알고리즘 탐구 4. 애너그램 그룹 (풀이, 남의 코드 분석) (1) | 2023.04.02 |
| (C++)알고리즘 탐구 2. 문자열 뒤집기(풀이, 남의 코드 분석) (0) | 2023.03.31 |
| (C++)알고리즘 탐구 1. 유효한 팰린드롬 (풀이, 남의 코드 분석) (0) | 2023.03.30 |