참고도서 : 파이썬 알고리즘 인터뷰 . 박상길 . 책만 . 2020
참고도서에서 언급하는 알고리즘 주제를 참고하여 C++로 풀어보는 것을 목표로 합니다.
알고리즘을 공부하면서도 소프트웨어적 설계를 추가합니다. 답을 내는 코드를 짜는게 아니라 각각이 모듈이 되어 서로 맞물려 동작하는 코드를 짜는 것을 목표로합니다. (그래서 다른 글보다 코드가 깁니다.)
참고로 상위 레벨의 코드를 볼 수록
using namespace std; 라는 코드가 보이지 않아, 없이 진행합니다.
애너그램은 단어를 재배열해서 다른 단어로 만드는 것을 말합니다.
우선 책에서 언급하는 문제는 그룹 애너그램이라는 문제입니다.
책의 문제와 완벽히 유사한 문제가 백준에 있습니다.
(그러나 책에 있는 문제는 못풀었습니다.)
그 전에 다른 애너그램 문제들을 훑으면서 지나가겠습니다.
1919번: 애너그램 만들기
두 영어 단어가 철자의 순서를 뒤바꾸어 같아질 수 있을 때, 그러한 두 단어를 서로 애너그램 관계에 있다고 한다. 예를 들면 occurs 라는 영어 단어와 succor 는 서로 애너그램 관계에 있는데, occurs
www.acmicpc.net

애너그램이 되려면 몇개의 단어를 제거해야하나요?
정말 간단한 문제입니다.
aabbcc와 xxyybb에서 서로 겹치는 단어는 무엇이있는가? 이걸 확인하면 되지 않을까요?
그러나 한 가지 문제가 더 예상됩니다.
aabb 와 ccaaa 인 경우 입니다. 그러면 a를 하나 때어버려야 하는 상황입니다.
일치하는가로 찾게되면 문제가 생깁니다.
그러면 겹치는 것을 제거할까?
문자열에서 중간에 무언가를 제거하는 경우 index를 reset하는 과정에서 많은 시간적 손해가 생깁니다.
그러면 이전의 시간과 동일한 방법을 적용해야할 것으로 보입니다. 각 단어의 알파벳 개수를 구합니다.
그리고 abs(Lsm[0] - Rsm[0]) 를 진행하면서 그 값들을 모두 더한다면요?
일단 말로는 어려우니 일단 코드로 짜보도록 하겠습니다.
그러면 두 개의 함수를 사용합니다.
alpabet_count 와 retrunSolution 으로 하겠습니다.
alpabet_count는 string과 vector참조값을 입력받습니다.
retrunSolution의 경우는 각 벡터를 참고하여 int를 반환합니다.
그러면 뼈대를 만듭시다.
alpabet_count 이 함수는 이전에 만들었으니 그대로 가져옵니다.
void count_Alphabet(const std::string& sentence, std::vector<int>& alphabet) {
for (auto& i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}
int returnSolution(const std::vector<int>& Lsm, const std::vector<int>& Rsm) {
}
int main() {
std::vector <int> Lsm;
std::vector <int> Rsm;
}혹시나 count_Alphabet에 대한 설명이 필요하다면..
vector[0] = 0 일때 vector[0]은 어떤 알파벳을 count 하고 있을까요? a 입니다.
그러면 'a' - 'a' = 0 입니다. 그러니 우리는 조건문을 26번 작성할 필요없습니다.
'b' - 'a' = 1 인 것처럼 조건문을 한 번만 사용해도 충분합니다.
그러면 이제 내용을 넣어봅시다. 우선 main()문의 행동을 입력해봅시다.
#include <iostream>
#include<string>
#include<vector>
void count_Alphabet(const std::string& sentence, std::vector<int>& alphabet) {
for (auto& i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}
int returnSolution(const std::vector<int>& Lsm, const std::vector<int>& Rsm) {
}
int main() {
std::vector <int> Lsm(26, 0);
std::vector <int> Rsm(26, 0);
std::string L; std::string R; std::cin >> L; std::cin >> R;
count_Alphabet(L, Lsm);
count_Alphabet(R, Rsm);
std::cout << returnSolution(Lsm, Rsm);
}뭐 이런식으로 하겠죠? 그러면 우리가 Lsm, Rsm을 함수에 넣어주면 답을 뱉을 것입니다.
int returnSolution(const std::vector<int>& Lsm, const std::vector<int>& Rsm) {
int answer = 0;
for (int i = 0; i < Lsm.size(); i++) {
answer += std::abs(Lsm[i] - Rsm[i]);
}
return answer;
}결국 왼쪽string의 a총 모음과 오른쪽 string의 a의 총모음을 빼고 abs 취하면 됩니다.
그 값을 계속 더해나가고 그 값을 리턴하면 정답일 것

일단 문제가 없으니 제출합니다.
전체 코드는 이렇습니다.
#include <iostream>
#include<string>
#include<vector>
void count_Alphabet(const std::string& sentence, std::vector<int>& alphabet) {
for (auto& i : sentence) {
if (i >= 'a' and i <= 'z')
alphabet[i - 'a']++;
}
}
int returnSolution(const std::vector<int>& Lsm, const std::vector<int>& Rsm) {
int answer = 0;
for (int i = 0; i < Lsm.size(); i++) {
answer += std::abs(Lsm[i] - Rsm[i]);
}
return answer;
}
int main() {
std::vector <int> Lsm(26, 0);
std::vector <int> Rsm(26, 0);
std::string L; std::string R; std::cin >> L; std::cin >> R;
count_Alphabet(L, Lsm);
count_Alphabet(R, Rsm);
std::cout << returnSolution(Lsm, Rsm);
}
쉽네요.
조금 재미나게 짜신 분들이 있을까하고 다른 코드를 살펴보았습니다.
대부분 비슷한거 같고, 특이 케이스가 없어서 넘어가도록 하겠습니다.
대부분 함수로 나누지 않고, 각각의 계산을 행하셨습니다.
다음 문제입니다.
3778번: 애너그램 거리
만약 단어 A의 알파벳 순서를 바꿔서 단어 B를 만들 수 있다면, 두 단어는 애너그램이라고 한다. 예를 들어, occurs는 succor의 애너그램이지만, dear는 dared의 애너그램이 아니다. 영어에서 가장 유명
www.acmicpc.net

방금 풀었던 문제와 정확히 일치하는 문제라고 볼 수 있다.
달라진 점은 여러번 진행을 한다는 점..
코드를 살짝만 바꿔버리자.
main만 바꾸면된다.
int main() {
std::vector <int> Lsm(26, 0);
std::vector <int> Rsm(26, 0);
std::string L; std::string R; std::cin >> L; std::cin >> R;
count_Alphabet(L, Lsm);
count_Alphabet(R, Rsm);
std::cout << returnSolution(Lsm, Rsm);
}이걸 입력과 출력 양식만 바꿔주면 된다.
int main() {
int t; std::cin >> t;
int count = 1;
while (t--) {
std::vector <int> Lsm(26, 0);
std::vector <int> Rsm(26, 0);
std::string L; std::string R; std::cin >> L; std::cin >> R;
count_Alphabet(L, Lsm);
count_Alphabet(R, Rsm);
std::cout << "Case #" << count << ": " << returnSolution(Lsm, Rsm);
count++;
}
}결국 이게 함수로 나눠짜는 묘미가 아닐까 싶다.
작업을 진행하는 부분과 선언과 출력을 담담하는 부분이 구분되어있다.
그렇기 때문에 손쉽게 대응시킬 수 있다.
문제는다음과 같다.
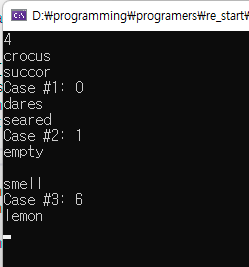
공백을 못받아 먹는다. 그러므로 line으로 받아먹게 수정을 해야할 듯 하다.
int main() {
int t; std::cin >> t;
std::cin.ignore();
int count = 1;
while (t--) {
std::vector <int> Lsm(26, 0);
std::vector <int> Rsm(26, 0);
std::string L; std::string R; getline(std::cin, L); getline(std::cin, R);;
count_Alphabet(L, Lsm);
count_Alphabet(R, Rsm);
std::cout << "Case #" << count << ": " << returnSolution(Lsm, Rsm) << std::endl;
count++;
}
}
오키 해결.

그러나 내 코드는 시간초가가 걸려버렸다.
지금의 알고리즘이 문제가 있다는 소리이다.
질문게시판을 참고하니까..
std :: endl 을 사용하지 말아라와 맨 위에 3가지를 넣으라고 합니다.
int main() {
std::ios::sync_with_stdio(0);
std::cin.tie(0);
std::cout.tie(0);
int t; std::cin >> t;
std::cin.ignore();
int count = 1;
while (t--) {
std::vector <int> Lsm(26, 0);
std::vector <int> Rsm(26, 0);
std::string L; std::string R; getline(std::cin, L); getline(std::cin, R);;
count_Alphabet(L, Lsm);
count_Alphabet(R, Rsm);
std::cout << "Case #" << count << ": " << returnSolution(Lsm, Rsm) << '\n';
count++;
}
}
근데, 이걸 넣고 시간초과가 풀린다는게
이게 맞는건가 싶네요
gpt 상으로는 실무에서도 사용될 수 있다고는 합니다. 근데, 좀 그렇네요..
알고리즘 짜는 코테와 이게 무슨 연관이 있을지..
어서 다음문제로 들어갑시다.
6996번: 애너그램
첫째 줄에 테스트 케이스의 개수(<100)가 주어진다. 각 테스트 케이스는 한 줄로 이루어져 있고, 길이가 100을 넘지 않는 단어가 공백으로 구분되어서 주어진다. 단어는 알파벳 소문자로만 이루어
www.acmicpc.net
이 문제부터는 알고리즘을 뜯어 고쳐야합니다.
애너그램의 가장 큰특징은 정렬을 시키면 그 둘은 같습니다.
이를 활용해서 문제를 풀면 끝납니다.
그래서 anargram 이라는 함수를 만들고 다시 뼈대를 만들어 봅시다.
anargram은 bool 을 반환하고 string을 매개변수로 받습니다.
const로 선언하면 안됩니다. 그러면 매개변수로 받아와도 정렬을 못합니다.
그리고 참조값을 보내면 안됩니다. 정렬을 하면서 L과 R값을 잃어버립니다.
마지막에 cout 을 통해서 L과 R을 출력해야합니다. 그러면 참조를 시키면 정렬하면 정렬된 값을 출력하게 됩니다.
뼈대를 만들어 보겠습니다.
#include <iostream>
#include<string>
bool anargram(std::string L, std::string R) {
}
int main() {
}main문을 먼저 만들어봅시다.
횟수를 정하고, 단어를 입력받고 함수에 보내고 출력하면 됩니다.
int main() {
int t; std::cin >> t;
while (t--) {
std::string L, R; std::cin >> L >> R;
if (anargram(L, R) == true)
std::cout << L << " & " << R << " are anagrams." << "\n";
else
std::cout << L << " & " << R << " are NOT anagrams." << "\n";
}
}
그러면 애너그램을 판단하는 함수를 작성합시다.
정렬하고 같으면 true 출력하고, 아니면 false 출력하면됩니다.
"다음의 코드는 틀렸습니다."
#include<algorithm>
bool anargram(std::string L, std::string R) {
if (std::sort(L.begin(), L.end()) == std::sort(R.begin(), R.end()))
return true;
else
return false;
}저는 이렇게 짤 수 있는줄 알았는데
sort는 반환값이 없어서 따로 선언한 후에 비교를 해야한다고 합니다.
그래서 이렇게 짤 수 있습니다.
bool anargram(std::string L, std::string R) {
std::sort(L.begin(), L.end());
std::sort(R.begin(), R.end());
if ( L == R)
return true;
else
return false;
}그래서 다음처럼 코드가 짜집니다.
#include <iostream>
#include<string>
#include<algorithm>
bool anargram(std::string L, std::string R) {
std::sort(L.begin(), L.end());
std::sort(R.begin(), R.end());
if ( L == R)
return true;
else
return false;
}
int main() {
int t; std::cin >> t;
while (t--) {
std::string L, R; std::cin >> L >> R;
if (anargram(L, R) == true)
std::cout << L << " & " << R << " are anagrams." << "\n";
else
std::cout << L << " & " << R << " are NOT anagrams." << "\n";
}
}
답은 뭐 맞는거 같은데 제출을 해봅시다.

맞습니다.
다음 문제로 넘어갑니다.
6566번: 애너그램 그룹
크기가 가장 큰 애너그램 다섯 개를 출력한다. 만약, 그룹의 수가 다섯개보다 작다면, 모두 출력한다. 그룹은 크기가 감소하는 순으로, 크기가 같을 때는 각 그룹에서 가장 사전 순으로 앞서는
www.acmicpc.net

이 문제가 현재 책에 나와있는 문제다.
일단 난이도가 상당히 높다..
나는 틀렸다. 조금 더 수련이 필요할 것으로 보입니다.
책은 파이썬 책이라 손쉽게 풀어내는데.. C++이라 그런가 너무 어렵다..
hash_map, map, queue 에 대해서 배우고 나서 그들의 활용도를 먼저 배우면서 진행을 해야하는 문제로 보입니다.
정렬부분에서 막히는것 같습니다. 그걸 큐랑 어찌저찌 엮어서 하는 문제로 보입니다.
대충 틀렸던 코드는 남겨놓겠습니다.
해뜨네.. 망할
자료구조가 부족해서 남의 코드는 분석을 못하겠네요..
STL 좀 공부를 해야하나 싶습니다.
#include <iostream>
#include<string>
#include<vector>
#include<map>
#include<algorithm>
bool compare(const std::vector<std::string>& a, const std::vector<std::string>& b) {
return a[0] > b[0];
}
int main() {
std::map<std::string, std::vector<std::string>> words;
std::string line;
std::string sort_str;
bool hi = true;
while (!std::cin.eof()) {
getline(std::cin, line);
if (line != "") {
hi = false;
sort_str = line;
sort(sort_str.begin(), sort_str.end());
std::map<std::string, std::vector<std::string >> ::iterator it = words.find(sort_str);
if (it != words.end()) {
words[sort_str].push_back(line);
}
else {
std::vector<std::string> v;
v.push_back(line);
words.insert({ sort_str, v });
}
}
}
if (hi == true)
return 0;
std::vector<std::vector<std::string>> answer;
std::map<std::string, std::vector<std::string >> ::iterator it;
for (it = words.begin(); it != words.end(); ++it) {
it->second.push_back(std::to_string(it->second.size()));
std::sort(it->second.begin(), it->second.end());;
it->second.erase(std::unique(it->second.begin(), it->second.end()), it->second.end());
answer.push_back(it->second);
}
sort(answer.begin(), answer.end(), compare);
std::vector<std::string> temp;
for (int i = 0; i < answer.size()-1; i++) {
if (answer[i][0] == answer[i + 1][0]) {
if (answer[i][1] > answer[i + 1][1]) {
temp = answer[i];
answer[i] = answer[i + 1];
answer[i + 1] = temp;
}
}
}
int count = 0;
for (auto& i : answer) {
if (count == 5)
break;
std::cout << "Group of size " << i[0] << ": ";
for (int j = 1; j < i.size(); j++) {
std::cout << i[j] << " ";
}
std::cout << "." << "\n";
count++;
}
}
'ㅇ 공부#언어 > (C++) 알고리즘' 카테고리의 다른 글
| (C++)알고리즘 탐구 5. 브루트 포스 (1/2) (풀이, 알고리즘 분석) (1) | 2023.04.05 |
|---|---|
| C++ 코딩 테스트 기술 모음 (0) | 2023.04.03 |
| (C++)알고리즘 탐구 3. 가장 많은 글자. (풀이, 남의 코드 분석) (0) | 2023.04.01 |
| (C++)알고리즘 탐구 2. 문자열 뒤집기(풀이, 남의 코드 분석) (0) | 2023.03.31 |
| (C++)알고리즘 탐구 1. 유효한 팰린드롬 (풀이, 남의 코드 분석) (0) | 2023.03.30 |