팀원의 이야기를 적는 글이므로
전문성이 떨어지며 내용이 빈약합니다.
처음 계획은 음성 API를 통해서 자연어를 처리하는 방안이였으나,
계획이 조금 수정되어
음성을 직접 인식시켜보는 방향으로 접근을 하게되었습니다.
우리의 음성 데이터는 다음과 같은 형식으로 이루어져 있습니다.

제 전공지식으로 이해를 하면 음의 높낮이에 따라서 그림으로 표현되는 방식이겠죠.
음성을 분석하기 위해서 필요한 과정은 Fourier Transform
전기전자를 전공한 사람들은 질리도록 하고
생으로도 풀어보는 그 푸리에 변환입니다.
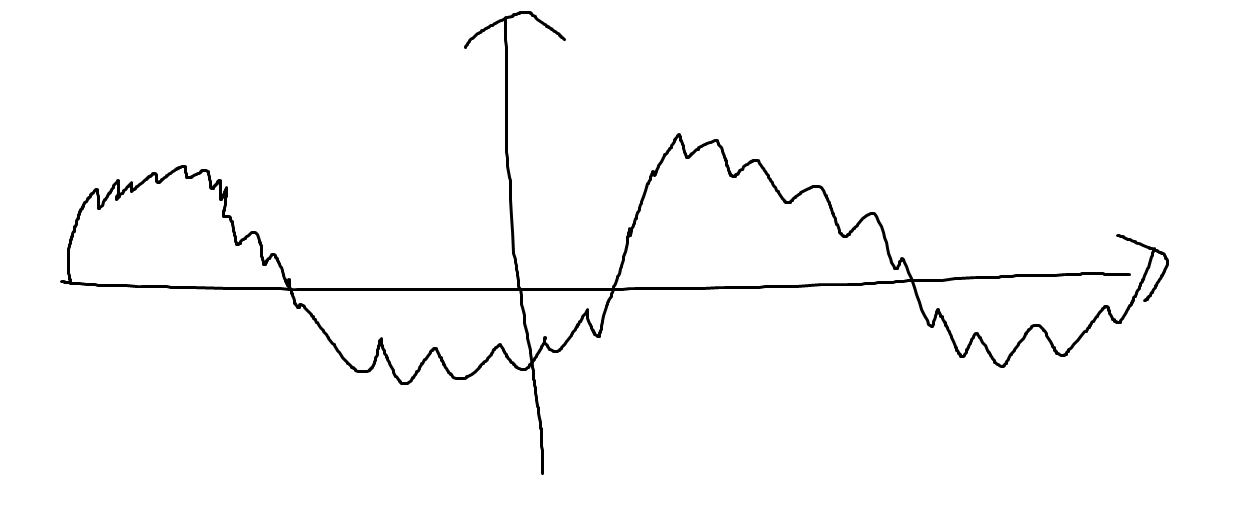
뭐 이런 느낌의 노이즈가 낀 신호가 있다면

노이즈와 사인파가 합쳐진 신호라고 볼 수 있습니다.
그러면 노이즈의 주파수와 사인파의 주파수로 그래프를 그리자면

이런식으로 그림이 그려지게 되겠죠.
이를 이제 필터를 통과시켜서 주파수 성분을 잘라내면
노이즈를 제거한 음성을 얻을 수 있습니다.
아마 제 이해가 맞다면 이렇게 음성을 분리하는 과정을 진행하고

사람은 저주파 대역에 더 민감하기 때문에 스펙트럼에 mel scale을 기반한 fliter bank인 mel filter bank를 적용시켜서 mel spectrum을 얻을 수 있고, 이를 시간 영역으로 megnitude 를 dB scale로 표현하면 mel spectrogram이 나온다고 합니다.
대충 필터 통과시켜서 구한 스펙트럼이라는 거 같습니다.
그래서 mel spectrum에 cepstral 분석 방식을 거치면 학습에 사용하기 좋은 mfcc가 나옵니다.
이를 학습시킨다고 하는 것을 보입니다.
여튼 학습시킨 데이터를

슬라이딩 윈도우 방식으로
약간 컨벌루션 느낌으로 슬라이딩 시키면서
각각의 특징을 알아냅니다.
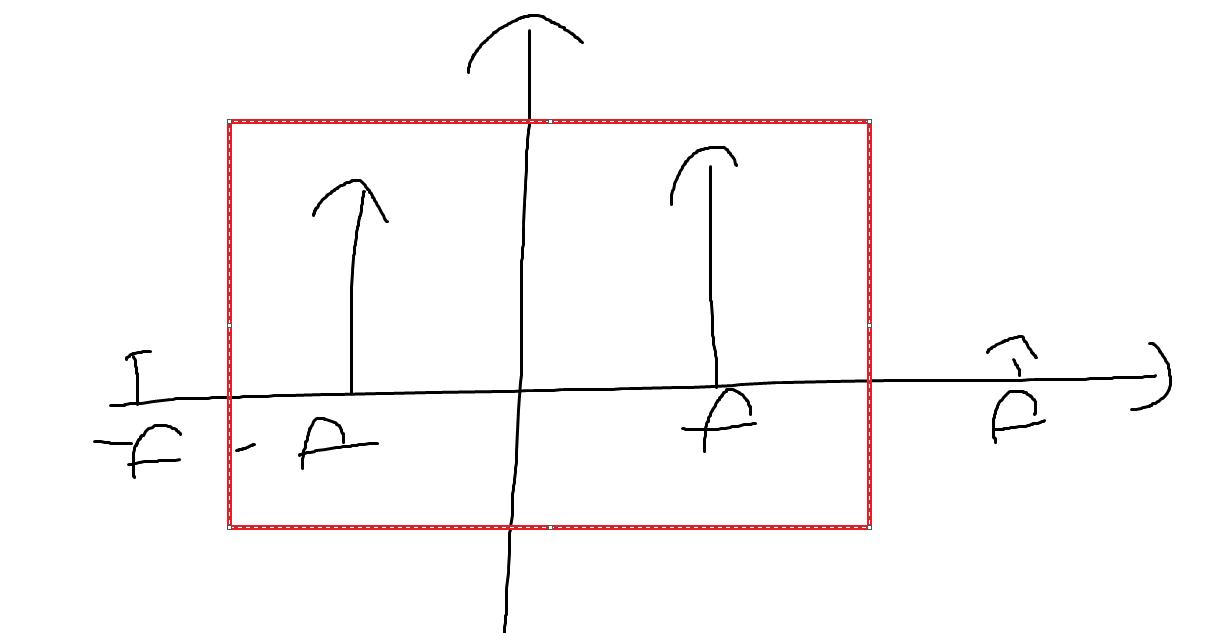
그래서 저희는 네 vs 아니요를 판단하는 것을 구현하였는데
슬라이딩 윈도우를 지나면서 네가 몇번 나오는지 아니요가 몇번나오는지 확인하면
지금 들어온 음성이 네인지 아니요 인지 구분이 가능해집니다.
팀원도 pose estimation을 담당한 저와 같게
잡음 데이터를 라벨로 분류함으로서
정확도를 올리면서
XGBoost를 (머신러닝) 사용하고
Augmentation을 수행해
네 아니요를 정확하게 판독하는 모델을 만들었습니다.
이에 대한 결과물은
다음 영상에서 시연영상을 올릴텐데 초반에서 확인 가능합니다.
'취업전 프로젝트 > TEAM_운동보조프로그램' 카테고리의 다른 글
| 8. (완성, 시연영상) 까꿍PT (0) | 2023.01.31 |
|---|---|
| 7. 데이터베이스 구현하기 및 완성 코드 (0) | 2023.01.31 |
| 5. Pose estimation 에서 스쿼트 자세를 측정하는 방법 (3) | 2023.01.31 |
| 4. 좌표로 접근을 해보자. (실험) (0) | 2023.01.16 |
| 3. 스쿼드 사진 찍고, 라벨링 진행중 (0) | 2023.01.16 |